6 Probabilidades
Neste capítulo são apresentados os principais conceitos, frequentemente designados por teoria da probabilidade ou por introdução à probabilidade. Começam por ser apresentadas as definições mais elementares que, mais à frente, serão utilizadas para introduzir conceitos mais complexos e abstratos. Trata-se de uma leitura fundamental para compreender toda a teoria estatística.
6.1 Conceitos fundamentais
A maior parte da estatística envolve, de uma ou outra forma, probabilidades. Embora todos tenhamos uma noção do que são probabilidades, pois estas estão associadas a decisões que tomamos diariamente, quando se pretende definir os conceitos de forma mais genérica e abstrata, surgem dificuldades. Esta secção apresenta os conceitos elementares associados às probabilidades.
6.1.1 Experiências aleatórias
As probabilidades são sempre associadas a contextos de incerteza. Frequentemente, aparecem situações em que, perante as mesmas condições iniciais, o resultado de algo é incerto. Na Estatística estas situações são designadas por experiências aleatórias. Mais formalmente, para que se esteja perante uma experiência aleatória é necessário:
- Haver dois ou mais resultados possíveis.
- Haver incerteza sobre o resultado.
Trivialmente, é possível enumerar exemplos clássicos de experiências aleatórias: lançar uma moeda, lançar um dado, selecionar, ao acaso, uma carta de um baralho ou uma bola de uma urna, etc.
Numa análise mais superficial, em qualquer dos exemplos apontados, as duas condições enumeradas parecem estar reunidas. No entanto, numa análise mais profunda, em qualquer um dos exemplos, se fosse possível reunir as mesmas condições iniciais e repetir o procedimento exato, rapidamente se constata que teria que se obter sempre o mesmo resultado.
Tome-se o exemplo do lançamento de uma moeda. Caso as condições iniciais do lançamento possam ser replicadas de forma exata, o resultado do lançamento será sempre o mesmo, pois o fenómeno apenas está sujeito às leis da física.
No entanto, quando uma pessoa lança uma moeda à mão, é muito difícil, garantir ou controlar as condições iniciais de cada lançamento: velocidade, ângulo de saída, momento angular, distância ao solo, etc. Por este motivo, o resultado do lançamento de uma moeda por uma pessoa é considerado incerto.
Em geral, sempre que o resultado de uma experiência é muito sensível às condições iniciais pode ser mais prático tratar o fenómeno como aleatório, como nos casos enumerados atrás (moeda, dado, cartas, urna e outros).
Dica
Uma forma de obter sequências aleatórias consiste precisamente em utilizar dispositivos muito sensíveis às condições iniciais. Por exemplo, o lançamento de um dado é um desses dispositivos, gerando sequências de resultados indistinguíveis de sequências verdadeiramente aleatórias.
Na prática, independentemente da fonte da incerteza, quer advenha das condições iniciais, quer advenha do fenómeno em si, podemos aplicar o conceito de experiência aleatória de forma indistinta.
6.1.2 Espaços amostrais
Um espaço amostral tem uma definição muito simples: trata-se do conjunto de todos os resultados possíveis de uma experiência aleatória. Os espaços amostrais podem ser classificados em:
Espaços amostrais discretos: o conjunto de resultados pode ser enumerado. Estes espaços amostrais podem ser finitos ou infinitos.
Um exemplo de um espaço amostral finito são os resultados possíveis no lançamento de um dado, ou seja, o conjunto {1, 2, 3, 4, 5, 6}.
Já um espaço amostral infinito pode ser exemplificado pelas sequências de resultados até obter 6 no dado, ou seja, {6, 16, 26, …, 116, 126, … 216, 226, … 1116, 1126, …}.
Espaços amostrais contínuos: o conjunto de resultados é um valor num determinado intervalo real. Estes espaços amostrais são sempre infinitos, mesmo que se trate de intervalos fechados.
Um exemplo de um espaço amostral contínuo pode ser o intervalo que decorre entre duas chegadas a uma fila de espera, que será um valor no intervalo [0, +\(\infty\)[.
Por norma, o conjunto de resultados de um espaço amostral é designado pela letra grega \(\Omega\).
Note-se que na Secção 1.2.2 fez-se uma distinção semelhante a propósito dos diferentes tipos de dados estatísticos. De facto, uma observação de uma variável estatística também é um elemento de entre um conjunto de valores possíveis.
6.1.3 Acontecimentos
Apoiados nos dois conceitos anteriores podemos agora definir um acontecimento, como um subconjunto do espaço amostral.
Geralmente, falamos de acontecimentos quando se pretende referir um subconjunto de resultados que têm alguma característica expressiva em comum. Por exemplo, no lançamento de um dado, podemos definir o acontecimento obter um número par, correspondendo ao conjunto {2, 4, 6}. No entanto, é possível definir um acontecimento que corresponda a um qualquer subconjunto arbitrário.
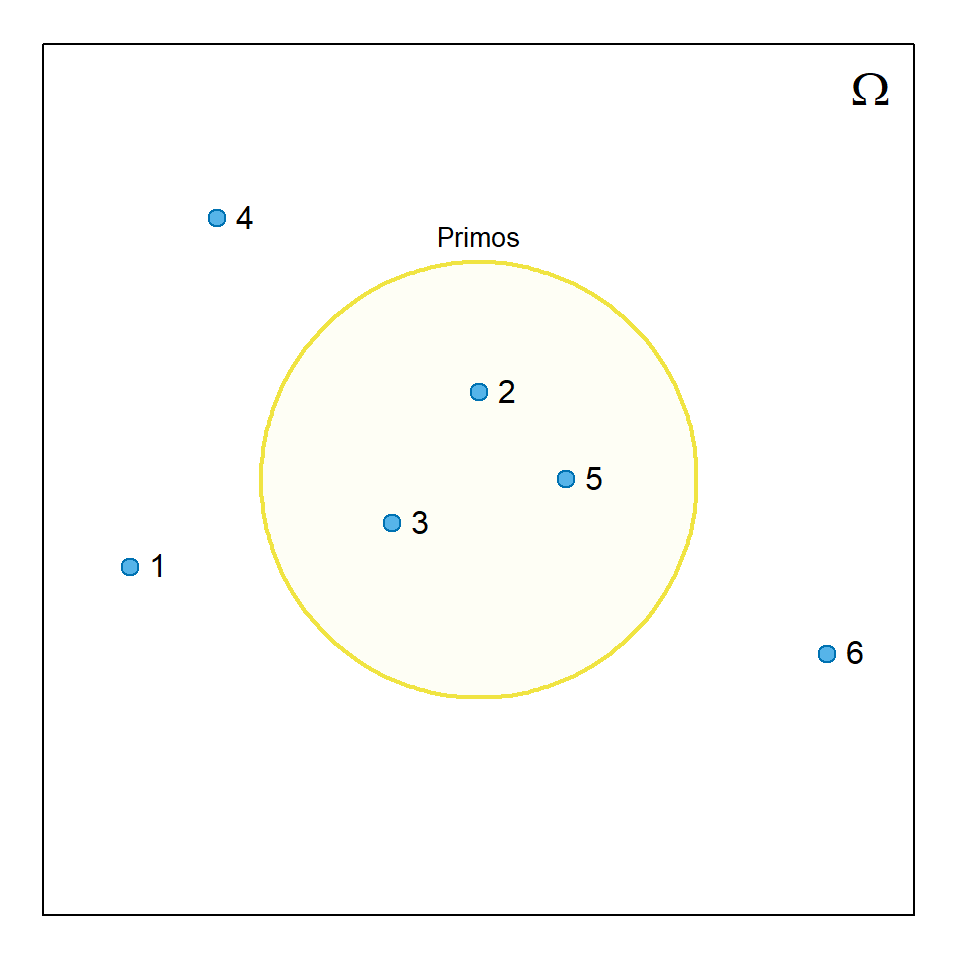
Os acontecimentos costumam ser designados por letras maiúsculas, A, B, C, etc., e podem ser representados num diagrama de Venn, tal como na Figura 6.1, onde se representa o espaço amostral do lançamento de um dado e o acontecimento obter um número primo.
Quando se trata de conjuntos, tal como é o caso dos acontecimentos, o diagrama de Venn é uma excelente visualização, pois permite intuir facilmente sobre as regras da álgebra de conjuntos. Por exemplo, na Figura 6.2 pode visualizar-se o resultado da aplicação de algumas regras algébricas sobre conjuntos.
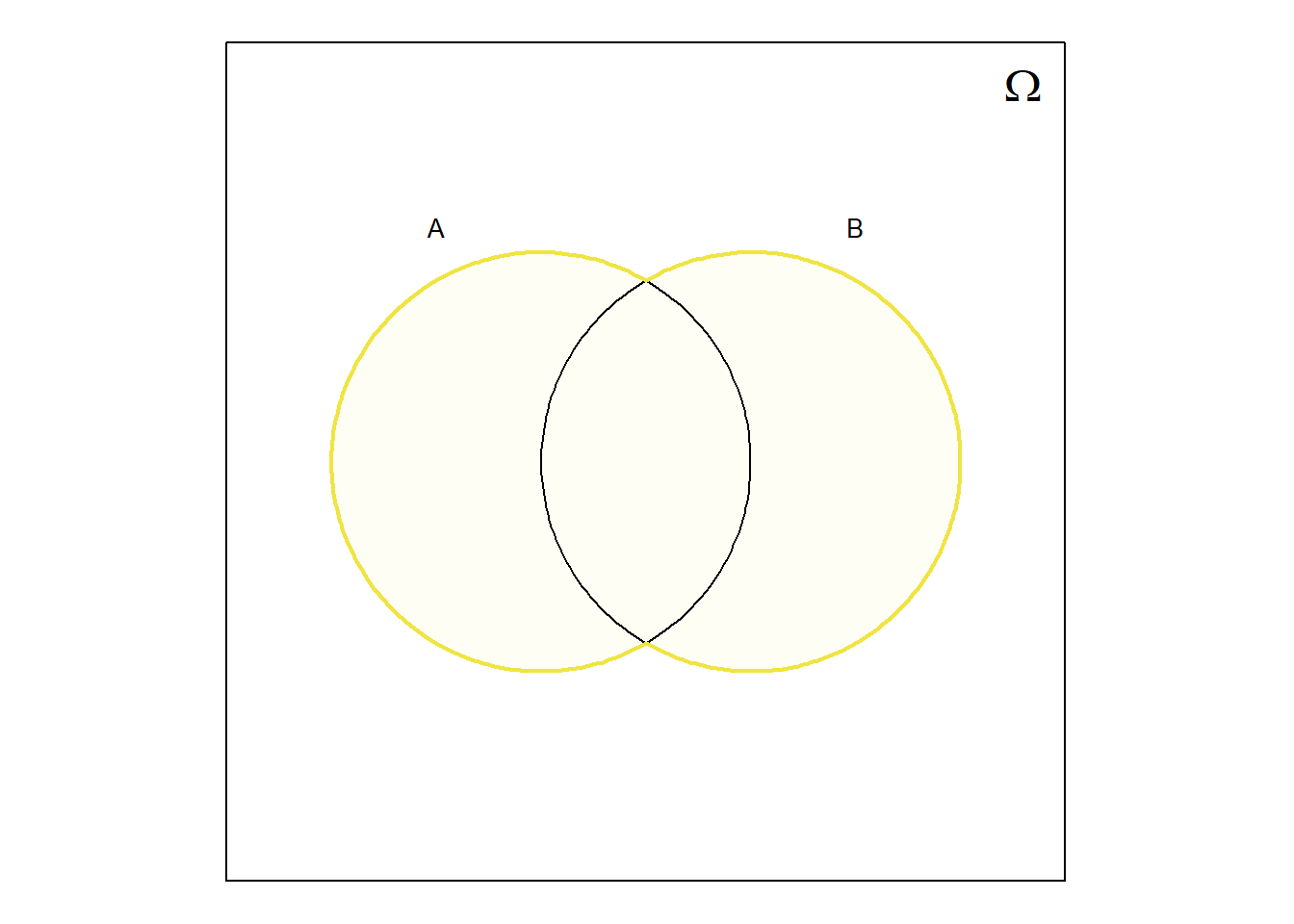
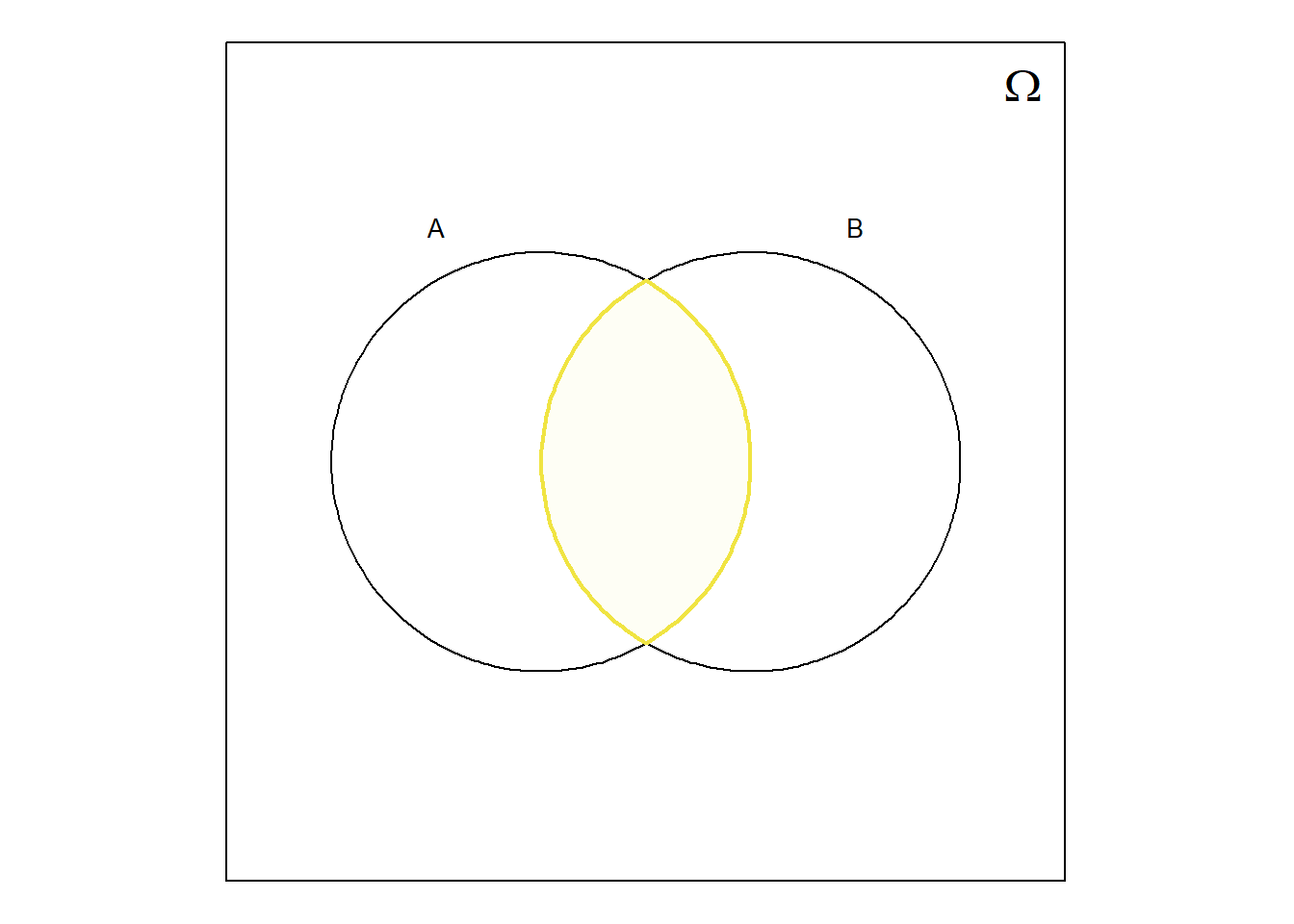
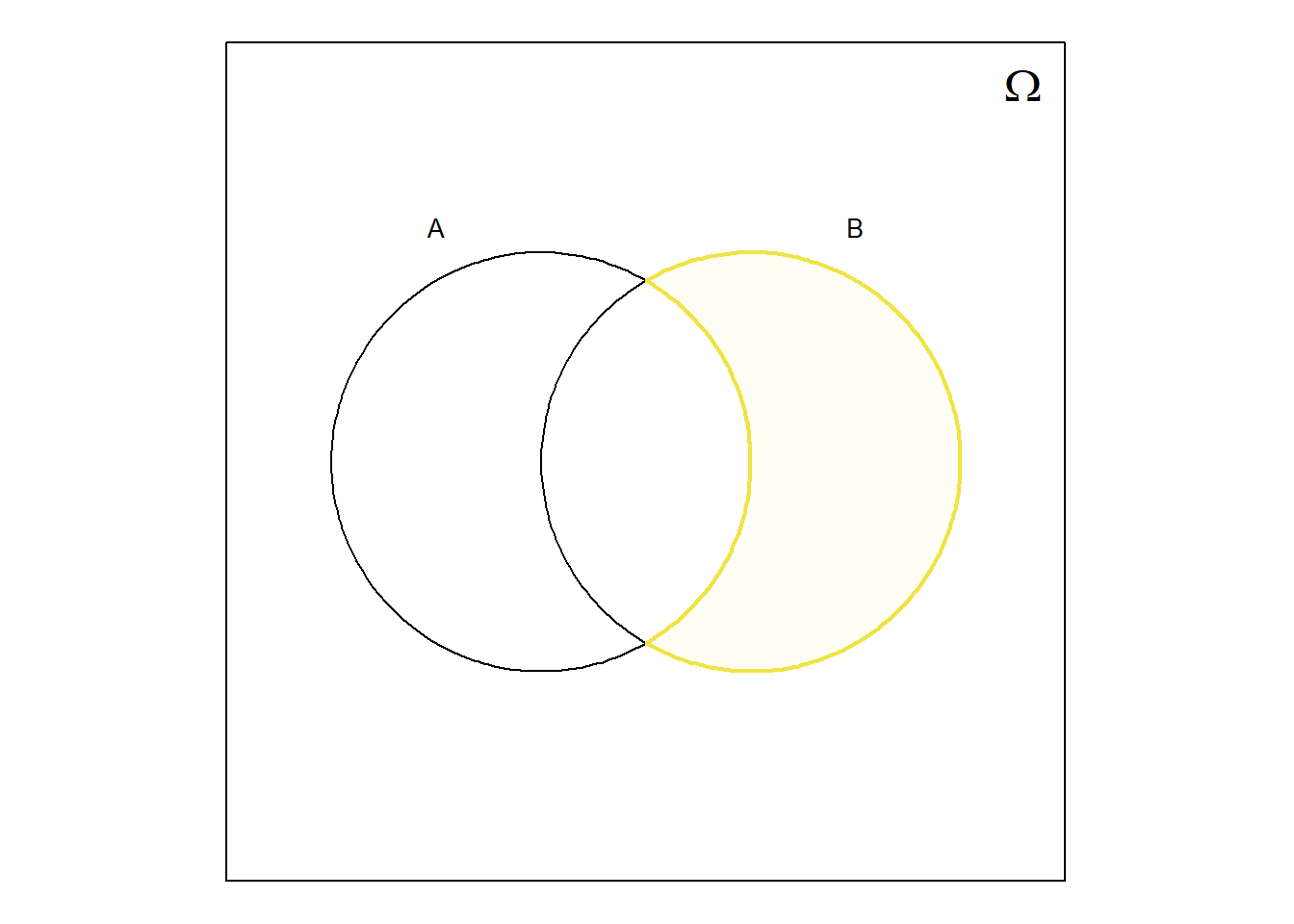
Em geral, qualquer regra que se aplique na álgebra de conjuntos também pode ser aplicada a acontecimentos para determinar os conjuntos resultantes das operações de reunião, interseção, etc., efetuadas sobre acontecimentos.
Há alguns acontecimentos notáveis, cujas definições se apresentam:
Acontecimento certo: é um acontecimento cujo conjunto de resultados inclui todos os elementos do espaço amostral.
O acontecimento definido por obter um ou mais pontos no lançamento de um dado inclui todos os elementos do espaço amostral.
Acontecimento impossível: é um acontecimento cujo conjunto de resultados é vazio.
O acontecimento definido por obter mais de 6 pontos no lançamento de um dado não inclui qualquer elemento do espaço amostral.
Acontecimento simples ou acontecimento elementar: é um acontecimento cujo conjunto de resultados é singular, i.e, contém apenas 1 resultado.
O acontecimento definido por obter 6 pontos no lançamento de um dado é um exemplo, uma vez que há apenas 1 resultado favorável ao acontecimento.
Acontecimentos mutuamente exclusivos ou acontecimentos disjuntos: são acontecimentos cujos conjuntos de resultados não têm elementos em comum, ou seja \(A \cap B = \emptyset\).
Um exemplo deste tipo de acontecimentos é obter 2 ou menos pontos e obter 5 ou mais pontos num lançamento do dado. Não há nenhum resultado que pertença aos dois conjuntos.
Acontecimentos complementares: são acontecimentos mutuamente exclusivos em que o conjunto de resultados que resulta da reunião é igual ao espaço amostral, ou seja \(A \cup \bar{A} = \Omega\). Para designar o complementar do acontecimento \(A\), utiliza-se \(\bar{A}\).
Um exemplo deste tipo de acontecimentos é obter um número par e obter um número ímpar num lançamento do dado. Note-se que os acontecimentos são mutuamente exclusivos e a reunião é o espaço amostral.
Dica
Todos os acontecimentos complementares são mutuamente exclusivos. O contrário nem sempre é verdade.
6.1.4 Probabilidade
Na linguagem comum, o termo probabilidade está associado à maior ou menor possibilidade ou frequência com que algum acontecimento tenha ocorrido ou venha a ocorrer. De facto, no dicionário, probabilidade está definida, entre outras aceções, como a frequência com que ocorre determinado acontecimento (Porto Editora, 2025).
Embora esta definição sirva na linguagem comum, na definição matemática é necessário mais rigor e precisão. Assim, ao longo do tempo foram apresentadas e desenvolvidos definições e conceitos associados à probabilidade.
Abordagem clássica
Dado o espaço amostral de experiência aleatória em que todos os resultados têm a mesma probabilidade de ocorrência, a probabilidade de um acontecimento é definida como o rácio entre o número de resultados favoráveis a esse acontecimento e o número de resultados possíveis.
Formalmente, se um espaço amostral for composto por \(R_1\), \(R_2\), …, \(R_n\) resultados diferentes e se um acontecimento \(A\) for definido sobre esse espaço amostral, então
\[P(A)=\frac{n_A}{n}\]
sendo \(n_A\) o número de elementos do espaço amostral pertencentes ao conjunto de resultados do acontecimento A.
Embora esta definição de probabilidade tenha um âmbito limitado, só sendo aplicável quando os diferentes resultados são equiprováveis, não deixa de ser aplicável a inúmeros casos com interesse prático.
DicaAplicação da definição clássica
Se, por exemplo, no lançamento de um dado, se pretender determinar a probabilidade de obter um número ímpar, podemos utilizar a definição clássica, admitindo que se trata de um dado perfeitamente equilibrado.
Seja A o referido acontecimento. Então,
\[P(A)=\frac{n_A}{n}=\frac{\#\{ 1, 3, 5\}}{\#\{ 1, 2, 3, 4, 5, 6\}} = \frac{3}{6} = \frac{1}{2} = 0.5\]
Abordagem frequencista
A maior limitação da abordagem clássica de probabilidade é ser aplicável apenas a espaços amostrais em que todos os resultados são equiprováveis. É fácil constatar que esta limitação é importante e inúmeras situações com interessa prático não poderiam ser tratadas. Por exemplo, na experiência do lançamento do dado, se não houver a certeza de se tratar de um dado perfeitamente equilibrado, a abordagem clássica não faria sentido.
Caso a experiência aleatória em causa possa ser repetida um número arbitrário de vezes, aquela limitação pode ser contornada utilizando a abordagem frequencista de probabilidade. Assim, a probabilidade de um acontecimento \(A\) pode ser calculada através do rácio entre o número de vezes que o acontecimento ocorre e o número de repetições, quando o número de repetições for arbitrariamente grande. Formalmente,
\[P(A)=\lim_{n\to\infty}\frac{n_A}{n} \tag{6.1}\] em que \(n\) é o número de vezes que se repete a experiência aleatória e \(n_A\) o número de vezes que, na experiência, o acontecimento \(A\) ocorreu. Note-se que, ao contrário da abordagem clássica, não se trata de uma probabilidade exata, mas de uma aproximação com base na frequência relativa do acontecimento. No entanto, a aplicação da Lei dos grandes números garante a convergência, quando o número de repetições é suficientemente grande.
NotaLei dos grandes números
No contexto da abordagem frequencista de probabilidade, a lei dos grandes números (LGN) garante que, à medida que o número de repetições tende para infinito, a probabilidade de um qualquer acontecimento definido no respetivo espaço amostral, converge para a verdadeira probabilidade desse acontecimento.
ImportanteA falácia do jogador
Uma interpretação falaciosa da LGN é conhecida coma a falácia do jogador, por ser especialmente popular entre jogadores de jogos fortuna e azar. Nesta versão da LGN algumas pessoas acreditam que, depois de ter azar várias vezes, o jogo (cartas, dados, etc.) lhe está em favor e que terá certamente que ser compensado devido à LGN.
Naturalmente, o facto de um acontecimento ter ou não ocorrido, não muda a probabilidade de ocorrência no futuro. Por exemplo, admita-se que uma moeda foi lançada 10 vezes, tendo sido obtidas 10 caras. A probabilidade de obter cara ou coroa no lançamento seguinte é a mesma dos anteriores, por hipótese, 0.5 cada face.
A moeda não está a dever uma coroa, pelo simples facto de que se trata de um objeto de metal inanimado, não possuindo contabilidade organizada. Igualmente, não existe nenhuma entidade ou força conhecida encarregue de manter os registos e o equilíbrio.
Na Figura 6.3 pode visualizar-se a convergência para a real probabilidade do acontecimento quando se utiliza a expressão Equação 6.1. No gráfico simula-se o resultado do lançamento de uma moeda 500 vezes. Por hipótese, a probabilidade teórica de sair cara é igual a 0.5.
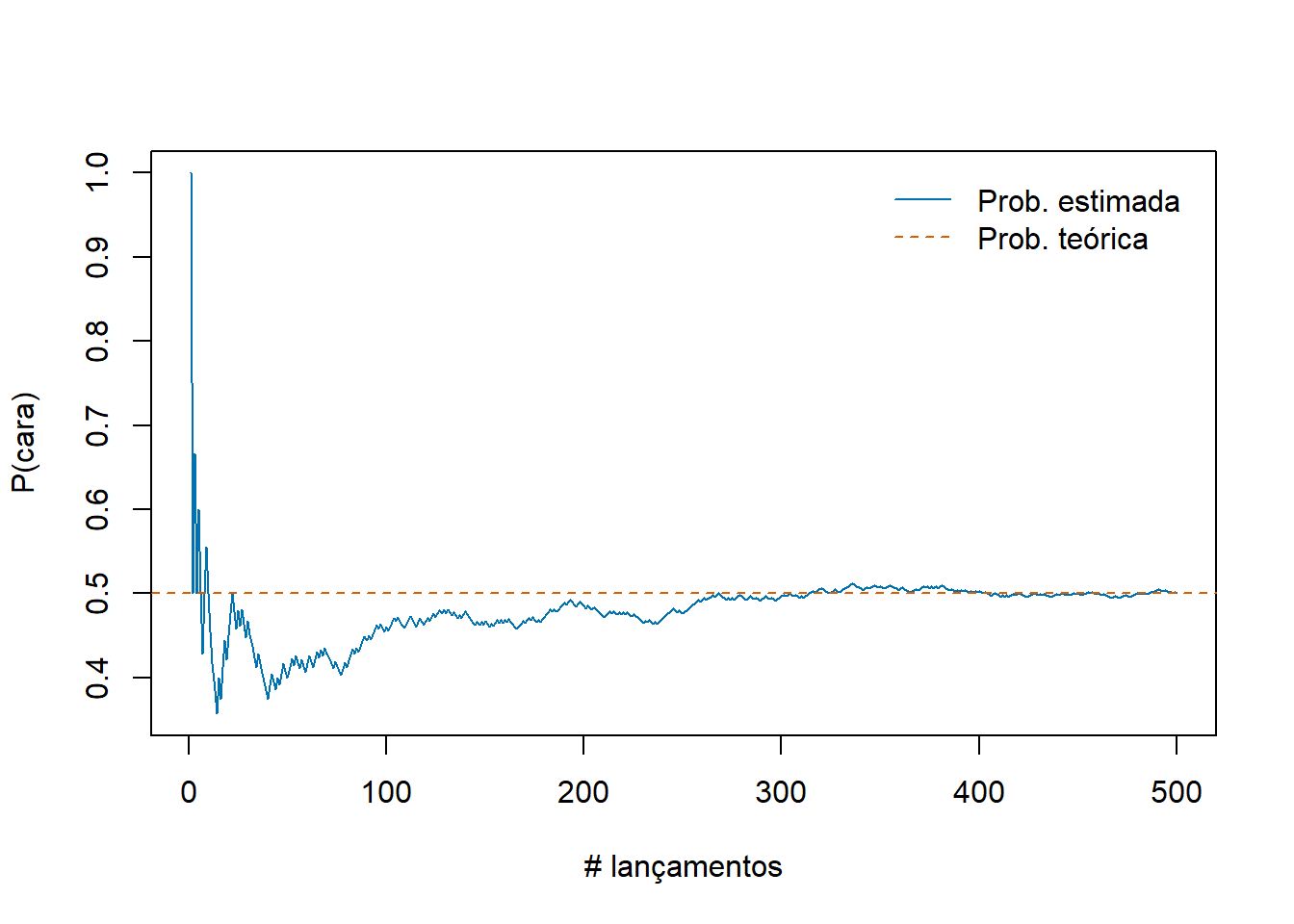
Note-se que, no contexto da LGN, a convergência não é monótona, isto é, o valor da probabilidade estimada nem sempre se aproxima da probabilidade teórica à medida que o número de repetições aumenta. Como se pode ver na figura, há períodos em que o valor estimado se afasta do valor teórico. Aliás, em termos absolutos, a diferença entre o número de caras obtido e o número de caras teórico tende a aumentar. No entanto, a probabilidade tende a convergir para o valor teórico pois o número de lançamentos (denominador) aumenta mais rapidamente.
Abordagem subjectiva
As abordagens descritas anteriormente são objetivas, no sentido em que há uma forma unívoca de calcular uma probabilidade. No entanto, apenas se aplicam em circunstâncias particulares, não sendo universais.
Para os subjetivistas, a probabilidade é um grau de crença, isto é, a probabilidade reflete a disposição de um indivíduo para acreditar na eventual ocorrência de um acontecimento. Este grau de crença pode variar de indivíduo para indivíduo e pode variar no tempo.
Desta forma, é possível atribuir probabilidades a qualquer acontecimento, mesmo aqueles que não é possível observar. Por exemplo, a probabilidade de haver outras formas de vida inteligentes na nossa galáxia.
Talvez a forma mais comum de interpretar a abordagem subjetiva seja imaginar uma situação em que, na ocorrência de um acontecimento, A, um agente racional recebe 1 unidade de uma qualquer utilidade (dinheiro, bens, etc.). Caso o acontecimento A não ocorra, recebe 0. O grau de crença em A é igual a \(p\) se \(p\) for o valor mínimo a que estaria disposto a vender aquela proposta (ou o valor máximo a que estaria disposto a comprar).
Note-se que, interpretada desta forma, a probabilidade terá um conjunto de características semelhante à abordagem clássica ou à abordagem frequencista. Por exemplo, a probabilidade fica limitada ao intervalo entre 0 e 1.
Abordagem axiomática
Embora as abordagens apresentadas até agora tenham o seu âmbito de aplicação e sejam úteis em muitos contextos, noutros casos, há a necessidade de uma abordagem mais precisa. Assim, a abordagem axiomática define um conjunto de regras abstratas (axiomas) a que as probabilidades devem obedecer. Esta abordagem foi introduzida em 1933 por Andrey Kolmogorov, sendo também conhecida como axiomática de Kolmogorov. Apresentam-se de seguida os referidos axiomas.
Considere-se um espaço amostral \(\Omega\) e seja \(P(A)\) a probabilidade de um qualquer acontecimento A.
Axioma 1
\[P(A)\in\mathbb{R}, P(A)\geq 0 \tag{6.2}\]
O axioma 1 garante que a probabilidade é um número real positivo.
Axioma 2
\[P(\Omega)=1 \tag{6.3}\]
O axioma 2, efetivamente, limita qualquer probabilidade a 1. Em conjunto com o axioma 1 podemos afirmar que, para qualquer acontecimento, A, \(0 \leq P(A) \leq 1\).
Axioma 3
Para quaisquer acontecimentos, A, B, C, …, mutuamente exclusivos,
\[P(A\cup B\cup C\cup\cdots)= P(A)+P(B)+P(C)+\cdots \tag{6.4}\]
A partir destes 3 axiomas, as probabilidades passam a ter um conjunto de propriedades a que devem obedecer, não importando como são interpretadas, se de forma objetiva ou subjetiva. Na Secção 6.1.5 serão apresentadas algumas regras práticas de cálculo que podem ser facilmente demonstradas a partir destes axiomas.
6.1.5 Algumas regras de cálculo
A partir dos axiomas enumerados anteriormente é possível deduzir uma série de regras para o cálculo de probabilidades.
\[P(A)+P(\bar{A})=1 \tag{6.5}\]
A Equação 6.5 pode ser facilmente deduzida a partir dos axiomas. Pela definição de complementaridade sabemos que \(A\cup\bar{A}=\Omega\). Então, \(P(A\cup\bar{A})=P(\Omega)\). Pelo axioma 1 sabemos que \(P(\Omega)=1\) e, como \(A\) e \(\bar{A}\) são mutuamente exclusivos, pelo axioma 2, \(P(A\cup\bar{A})=P(A)+P(\bar{A})\). Consequentemente, \(P(A)+P(\bar{A})=1\).
Sabemos também que o acontecimento impossível, \(\emptyset\), e o acontecimento \(\Omega\) são complementares. Logo podemos deduzir facilmente que
\[P(\emptyset)=0 \tag{6.6}\]
Uma outra regra que pode ser deduzida seguindo um raciocínio semelhante é a regra geral da adição:
\[P(A\cup B) = P(A) + P(B) - P(A\cap B) \tag{6.7}\]
A aplicação da Equação 6.7 pode ser visualizada na Figura 6.4 recorrendo à experiência aleatória do lançamento de um dado equilibrado. Definindo os acontecimentos A (número primo) e B (número par) é imediato constatar que \(A\cup B = \lbrace 2,3,4,5,6\rbrace\) e que \(P(A\cup B)=5/6\).
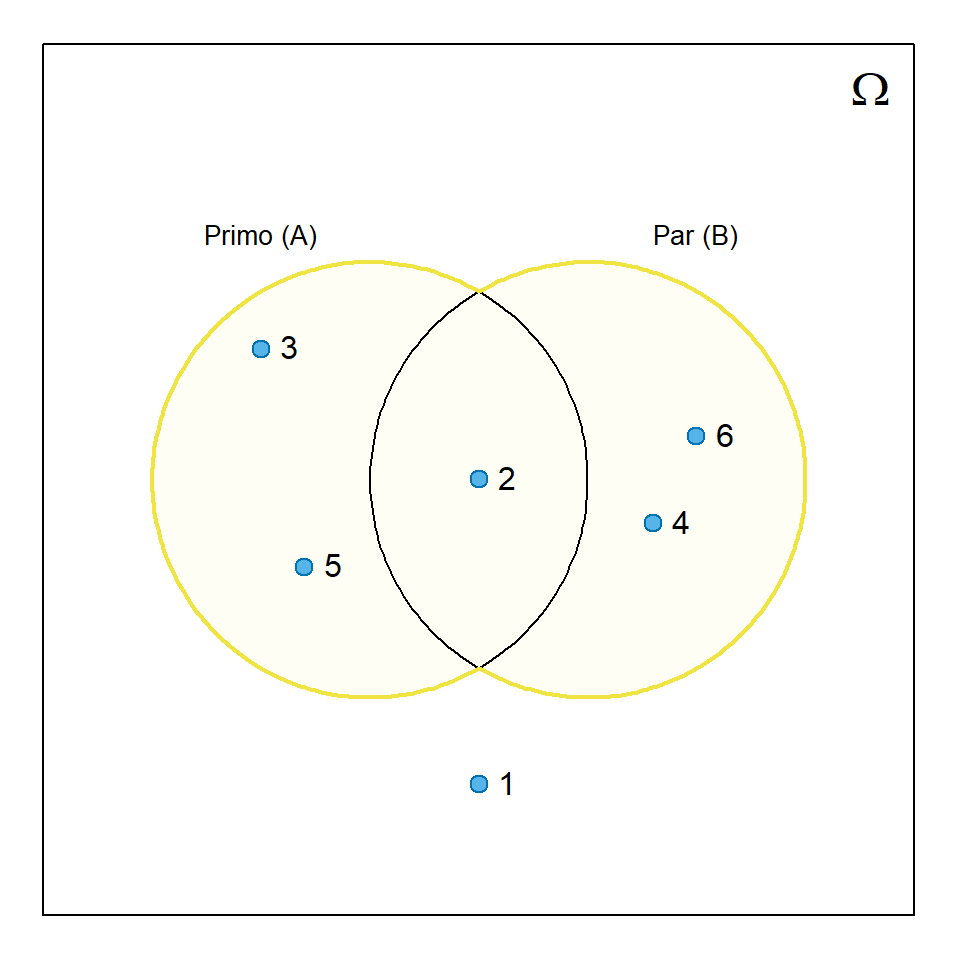
Aplicando a regra da adição, obtém-se exatamente o mesmo resultado:
\[ \begin{align} P(A\cup B) &= P(A) + P(B) - P(A\cap B)\\ &= P(\lbrace 2,3,5\rbrace) + P(\lbrace 2,4,6\rbrace) - P(\lbrace 2\rbrace)\\ &= 3/6 + 3/6 - 1/6\\ &= 5/6 \end{align} \]
6.1.6 Distribuições de probabilidade
No contexto de uma experiência aleatória, uma distribuição de probabilidade pode ser vista como uma função que descreve as probabilidades de cada um dos resultados do espaço amostral da experiência.
Considere-se o caso da experiência aleatória que consiste no lançamento de uma moeda. O espaço amostral, \(\Omega\), é o conjunto {cara, coroa}. A distribuição de probabilidade pode ser descrita por um vetor de probabilidades correspondentes a cada resultado, por exemplo, {0.5, 0.5}. O que a distribuição de probabilidade transmite é \(P(cara)=0.5\) e \(P(coroa)=0.5\).
Na prática, quando se trata de espaços amostrais discretos, é comum definir a distribuição de probabilidade com recurso a uma tabela. Por exemplo, na experiência aleatória que consiste no lançamento de um dado equilibrado, a distribuição de probabilidade poderia ser definida como na Tabela 6.1.
| Resultado | 1 | 2 | 3 | 4 | 5 | 6 |
| Probabilidade | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
Em vez de enumerar os resultados do espaço amostral, pode definir-se uma distribuição de probabilidade a partir de um conjunto de acontecimentos. Por exemplo no caso do dado, caso apenas interessasse o facto de o resultado ser par ou ímpar, a distribuição poderia ser definida pela Tabela 6.2.
| Resultado | par | ímpar |
| Probabilidade | 1/2 | 1/2 |
No caso de espaços amostrais contínuos a definição de uma distribuição de probabilidade é feita através de uma função densidade de probabilidade. Este tópico será abordado num capítulo posterior.
Independentemente de como a distribuição de probabilidade é definida, de forma a respeitar os axiomas definidos anteriormente, as seguintes propriedadedes terão que ser respeitadas:
- O conjunto de resultados ou acontecimentos, \(A_1\), \(A_2\), \(\cdots\), \(A_n\) é mutuamente exclusivo.
- \(0\leq P(A_i)\leq 1\), para qualquer resultado, \(A_i\).
- \(\sum_{i=1}^n{A_i}=1\), ou seja, a soma de todas as probabilidades deve ser 1, que pode ser assegurado se \(A_1\cup A_2\cup\cdots = \Omega\).
Como se pode verificar nos exemplos acima, todas as distribuições apresentadas respeitam estas 3 propriedades.
6.2 Probabilidades condicionais e independência
Considerem-se os dados do conjunto HairEyeColor que já tinham sido usados na Secção 5.1. Reproduz-se novamente a tabela de contingência contendo o número de alunos por cada categoria de quanto à cor dos olhos e quanto à cor do cabelo (Tabela 6.3).
Cabelo |
|||||
|---|---|---|---|---|---|
| Olhos | Black | Blond | Brown | Red | Total |
| Blue | 20 | 94 | 84 | 17 | 215 |
| Brown | 68 | 7 | 119 | 26 | 220 |
| Green | 5 | 16 | 29 | 14 | 64 |
| Hazel | 15 | 10 | 54 | 14 | 93 |
| Total | 108 | 127 | 286 | 71 | 592 |
| a Intencionalmente, os nomes das cores não foram traduzidos. | |||||
Considere-se agora uma experiência aleatória que consiste em selecionar um aluno ao acaso entre os 592 participantes do estudo. O espaço amostral desta experiência tem 592 resultados possíveis – um para cada aluno.
Naquele espaço amostral é possível definir um conjunto de acontecimentos relativos às cores dos olhos e do cabelo do aluno selecionado. Assim, relativamente à cor dos olhos podemos definir 4 acontecimentos (Blue, Brown, Green, Hazel) e relativamente à cor do cabelo podemos definir mais 4 acontecimentos (Black, Blond, Brown, Red).
Nos exemplos apresentados, não se vai utilizar o acontecimento Brown, pois tanto se poderia referir à cor dos olhos, como à cor do cabelo, o que seria confuso.
6.2.1 Probabilidades marginais
Para qualquer destes acontecimentos é fácil calcular as probabilidades de ocorrência, bastando aplicar a definição clássica de probabilidade, admitindo que todos os alunos têm a mesma probabilidade de serem selecionados (1/592).
Por exemplo a probabilidade de selecionar um aluno com olhos azuis (Blue) é
\[P(Blue)=\frac{215}{592} \approx 0.363\]
Já a probabilidade de selecionar um aluno de cabelo preto (Black) será
\[P(Black)=\frac{108}{592} \approx 0.182\]
As probabilidades calculadas designam-se por probabilidades marginais, pois representam a probabilidade de um acontecimento sem considerar outros acontecimentos.
ImportanteProbabilidades marginais
Uma probabilidade marginal diz respeito a um acontecimento, não considerando outros acontecimentos, também podem ser designadas por probabilidades simples. A designação marginal advém do facto de, tipicamente, serem anotadas nas margens das tabelas semelhantes à Tabela 6.3, representado as probabilidades dos acontecimentos nas linhas ou nas colunas.
O conjunto de acontecimentos relativos à cor do olhos (ou à cor do cabelo) forma aquilo a que se poderia designar por distribuição de probabilidade marginal, possuindo todas as propriedades enumeradas na Secção 6.1.6.
6.2.2 Probabilidades conjuntas e reunião
Quando se dispõe de uma tabela de contingência semelhante à Tabela 6.3 é simples calcular probabilidades conjuntas. Por exemplo a probabilidade de selecionar uma aluno de olhos azuis e de cabelo preto é
\[P(Blue\cap Black)=\frac{20}{592} \approx 0.034\]
Já para calcular probabilidades resultantes da reunião de acontecimentos, pode ser usada a regra da adição (Equação 6.7). Por exemplo, a probabilidade de selecionar um aluno de olhos azuis ou de cabelo preto é
\[ \begin{align} P(Blue\cup Black)&=P(Blue)+P(Black)-P(Blue\cap Black)\\ &=\frac{215}{592} + \frac{108}{592} - \frac{20}{592}\\ &=\frac{303}{592} \approx 0.512 \end{align} \]
Dica
Nunca é demais salientar, pois é causa de confusão frequente, que o conjunto \(Blue\cup Black\) inclui todos os alunos que tenham olhos azuis ou que tenham cabelo preto, podendo, deste modo, incluir alunos que tenham as duas características, ou seja, que pertençam ao conjunto \(Blue\cap Black\).
6.2.3 Probabilidades condicionais
Admita-se agora que se pretende calcular a probabilidade de ocorrência de um acontecimento, subordinada à ocorrência de um outro qualquer acontecimento. Por exemplo, a probabilidade de selecionar um aluno de olhos azuis, admitindo que o aluno selecionado (ou a selecionar) tem cabelo preto.
Dada a Tabela 6.3, o cálculo daquela probabilidade é intuitivo: admitimos que o aluno tem cabelo preto, logo, será um dos 108 alunos que partilham essa característica. Desses alunos, vamos selecionar um ao acaso, sabendo que há 20 alunos com olhos azuis nesse grupo. Logo, a probabilidade de selecionar um aluno de olhos azuis entre os alunos de cabelo preto terá que ser 20/108.
Em geral, se tivermos 2 acontecimentos, A e B, a probabilidade de ocorrer A condicionada pela ocorrência de B deve ser escrita como
\[P(A|B)\]
Podemos designar A como o acontecimento de interesse e B como condição. Assim, estamos interessados na probabilidade do acontecimento de interesse (A) dada uma determinada condição (B).
Dica
Quando estamos perante a notação \(P(A|B)\) lê-se probabilidade de A dado B ou probabilidade de A sabendo que B ou, simplesmente, probabilidade de A condicionada por B. Ou seja, o acontecimento B já ocorreu (ou admite-se que irá ocorrer) e queremos calcular a probabilidade de A nesse pressuposto.
No exemplo acima, na presença da Tabela 6.3, foi intuitivo calcular \(P(Blue|Black)\). Em geral, é possível calcular qualquer probabilidade condicionada utilizando a expressão Equação 6.8:
\[P(A|B)=\frac{P(A\cap B)}{P(B)} \tag{6.8}\]
Aplicando a expressão ao cálculo de \(P(Blue|Black)\) podemos obter o mesmo resultado de outra forma:
\[ \begin{align} P(Blue|Black) &= \frac{P(Blue\cap Black)}{P(Black)}\\ &=\frac{20/592}{108/592} =\frac{20}{108} \approx 0.185 \end{align} \]
6.2.4 Independência
O conceito de independência já foi mencionado na Secção 2.2 no contexto do estudo das relações entre variáveis estatísticas. No entanto, não foi apresentada uma definição formal de independência estatística, o que será feito nesta secção.
Dois acontecimentos dizem-se independentes quando a ocorrência de qualquer um deles não altera a probabilidade de ocorrência do outro.
A definição acima implica que, para acontecimentos independentes,
\[P(A|B)=P(A) \tag{6.9}\] \[P(B|A)=P(B) \tag{6.10}\]
que, atendendo à Equação 6.8, implica que
\[P(A\cap B)=P(A)\times P(B) \tag{6.11}\]
Intuitivamente, podemos verificar a Equação 6.11 através de um exemplo. Considere-se que se vai lançar uma moeda e um dado. Seja o acontecimento A obter cara na moeda e o acontecimento B obter 6 no dado. Por hipótese, podemos considerar \(P(A)=1/2\) e \(P(B)=1/6\). Naturalmente, os acontecimentos são independentes, pois não é conhecida qualquer forma de a moeda e o dado se influenciam mutuamente.
Qual deverá ser a probabilidade \(P(A\cap B)\)? Na moeda irá ocorrer cara em 1/2 dos lançamentos. Nesses lançamentos ir-se-á obter a face 6 em 1/6 dos lançamentos, ou seja, 1/6 de 1/2 ou, de outra forma, 1/6 \(\times\) 1/2 ou 1/12.
Note que, iniciar o raciocínio com o dado, produz o mesmo resultado, uma vez que a multiplicação é comutativa e, portanto, \(P(A\cap B)=P(B\cap A)\).
As expressões 6.9, 6.10 e 6.11 podem ser utilizadas para determinar se dois acontecimentos são independentes. Por exemplo, considere-se novamente a Tabela 6.3 e os acontecimentos ter olhos azuis (Blue) e ter cabelo preto (Black). Serão estes acontecimentos independentes?
Sabemos que \(P(Blue)=215/592\) e que \(P(Black)=108/592\). Logo, se os acontecimentos forem independentes, a probabilidade conjunta deveria ser
\[P(Blue\cap Black)=P(Blue)\times P(Black)=\frac{215}{592}\times\frac{108}{592}\approx 0.066\]
No entanto, já se viu que a probabilidade conjunta pode ser retirada diretamente da Tabela 6.3 e é igual a \(20/592 \approx 0.034\). Logo, os acontecimentos A e B não são independentes1.
A prova pode ser feita recorrendo a qualquer uma das três expressões, pois, qualquer uma delas, é condição suficiente para a independência. Por exemplo, cálculos anteriores já demonstraram que \(P(Blue|Black)\neq P(Blue)\), o que, por si só, seria suficiente para provar que os acontecimentos não são independentes.
Importante
A Equação 6.11 pode ser generalizada a mais do que 2 acontecimentos, ou seja, se houver \(n\) acontecimentos independentes, então
\[P(A_1\cap A_2\cap \cdots\cap A_n)=P(A_1)\times P(A_2)\times\cdots\times P(A_n) \tag{6.12}\]
Esta expressão é bastante útil para calcular a probabilidade conjunta de uma série de acontecimentos independentes. Por exemplo, pode ser utilizada para determinar a probabilidade de obter 10 caras seguidas no lançamento de uma moeda. Se \(A_i\) representar o acontecimento obter cara no lançamento \(i\), então,
\[ \begin{align} P(A_1\cap A_2\cap \cdots\cap A_{10})&=P(A_1)\times P(A_2)\times\cdots\times P(A_{10})\\ &=\frac{1}{2}\times\frac{1}{2}\times\cdots\times\frac{1}{2}\\ &=\left(\frac{1}{2}\right)^{10}=\frac{1}{1024}\approx 0.000977 \end{align} \]
6.3 Teorema de Bayes
Em alguns cenários, são conhecidas as probabilidades de um acontecimento ocorrer sob determinadas condições mas pretende-se saber a probabilidade de, tendo o evento ocorrido, se ter verificado a referida condição.
Um exemplo clássico da aplicação do teorema de Bayes está relacionado com os testes médicos. Por exemplo, num estudo de 2022 (Dinnes et al., 2022) reporta dados sobre os testes rápidos de antigénios para o vírus SARS-CoV-2, causador da doença designada por COVID-19. O estudo reporta que, em pessoas sem sintomas, suspeitas de terem estado em contacto com um infetado, os testes identificavam corretamente 64% dos indivíduos infetados. Para o mesmo grupo, os testes identificam corretamente 99.7% dos indivíduos não infetados.
Admitindo que, em determinada fase, os infetados eram 2% da população, há interesse em determinar qual a probabilidade de, um indivíduo que apresentasse um teste negativo, estar infetado pelo vírus.
Considerem-se os acontecimentos:
- \(I\): estar infetado, com \(P(I)=0.02\).
- \(\oplus\): testar positivo, com \(P(\oplus|I)=0.64\) (no caso dos infetados, um resultado correto é testar positivo).
- \(\ominus\): testar negativo, com \(P(\ominus|\bar{I})=0.997\) (no caso dos não infetados, um resultado correto é testar negativo).
Como os acontecimentos \(\oplus\) e \(\ominus\) são complementares, então, \(P(\ominus|I)=1-P(\oplus|I)=0.36\) e \(P(\oplus|\bar{I})=1-P(\ominus|\bar{I})=0.003\).
Nota
Nas ciências da saúde a probabilidade de um teste dar positivo, caso o indivíduo tenha uma dada doença ou condição clínica, é designada por sensibilidade. O acontecimento complementar, isto e, um teste negativo em indivíduos doentes é designado por falso negativo.
Paralelamente, a probabilidade de um teste dar negativo, caso o indivíduo não tenha a doença ou condição clínica, é designada por especificidade. Já o acontecimento complementar, isto e, um teste positivo em indivíduos não doentes é designado por falso positivo.
Quanto mais altos forem os valores de sensibilidade e especificidade e, consequentemente, quanto mais baixas forem as probabilidades de obter falsos negativos e falsos positivos, mais preciso é o teste.
Podemos facilmente calcular a probabilidade de interesse, \(P(I|\ominus)\), recorrendo à Equação 6.8.
\[ \begin{align} P(I|\ominus) &= \frac{P(I\cap\ominus)}{P(\ominus)} = \frac{P(I\cap\ominus)}{P(I\cap\ominus)+P(\bar{I}\cap\ominus)} \\ &= \frac{P(\ominus|I)\times P(I)}{P(\ominus|I)\times P(I)+P(\ominus|\bar{I})\times P(\bar{I})} \end{align} \]
Depois do desenvolvimento todas as probabilidades da fração são conhecidas, podendo ser calculado o resultado.
\[ P(I|\ominus)=\frac{0.36\times0.02}{0.36\times0.02+0.997\times0.98} = \frac{0.0072}{0.0072+0.97706} \approx 0.0073 \]
Neste caso, a probabilidade de um indivíduo que testou negativo estar infetado é pequena, cerca de 0.73%. O resultado faz sentido, uma vez que a incidência da doença é muito baixa e o teste tem elevada especificidade.
Nota
Ainda no âmbito das ciências da saúde o tipo de cálculo que se acabou de efetuar é muito relevante pois, embora a sensibilidade e especificidade do teste sejam importantes, o verdadeiro valor preditivo do teste também depende da prevalência da doença.
Podemos então falar no valor preditivo positivo (VPP), isto é, a probabilidade de o indivíduo estar doente quando o teste dá positivo, e no valor preditivo negativo (VPN), que é a probabilidade de o indivíduo não estar doente quando o teste dá negativo.
Mantendo os valores de sensibilidade e de especificidade constantes, à medida que a prevalência da doença aumenta, o VPP aumenta e o VPN diminui.
No exemplo desta secção, o VPN é cerca de 99.3% e o VPP cerca de 81.3%. Os cálculos para chegar a estes resultados são semelhantes aos apresentados, ficando como exercício para o leitor.
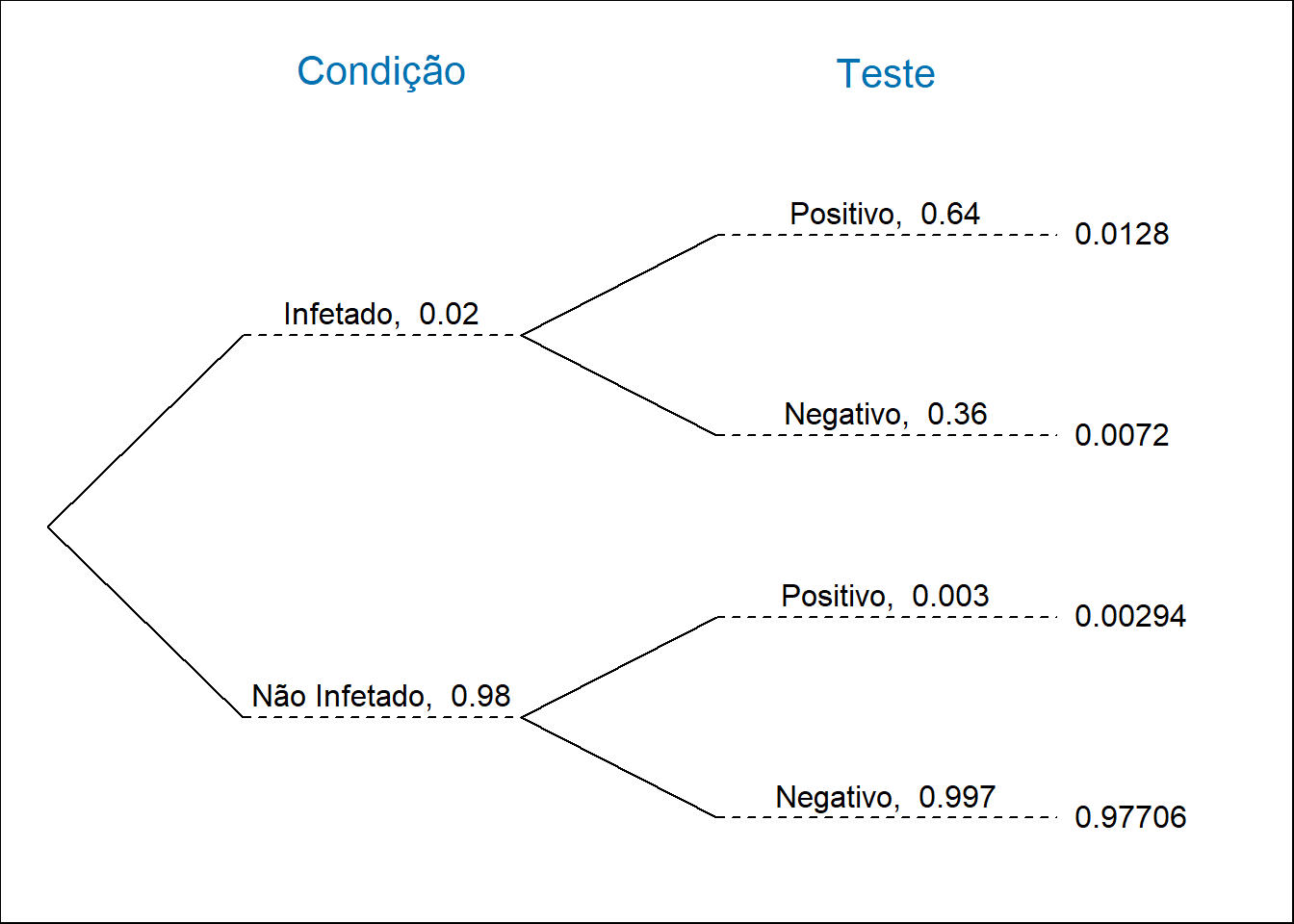
6.3.1 Diagrama de árvore
Uma forma particularmente intuitiva de visualizar este tipo de situações é utilizando o diagrama de árvore. Neste diagrama, a ramificação principal da árvore é utilizada para colocar as probabilidades dos acontecimentos condicionantes e, na ramificação secundária são colocadas as probabilidades condicionadas. Na terminação de cada ramo podem ser colocadas as probabilidades conjuntas.
A Figura 6.5 ilustra a aplicação do diagrama de árvore ao exemplo que se tem vindo a tratar.
6.3.2 Generalização
No caso analisado havia apenas dois acontecimentos condicionantes. No entanto, é possível aplicar a mesma lógica a qualquer número de acontecimentos, isto é, o teorema de Bayes pode ser ser generalizado. Considere-se:
Um conjunto de acontecimentos mutuamente exclusivos, \(A_1\), \(A_2\), … \(A_n\) em que \(\sum_i A_i = 1\) e para os quais se conhecem as probabilidades.
Um acontecimento, \(B\), para o qual se conhecem as probabilidades de ocorrência condicionais a cada \(A_i\), ou seja, \(P(B|A_i)\).
Nestas condições, sabe-se que
\[ \begin{align} P(B)&=P(A_1\cap B) + P(A_2\cap B) +\cdots+P(A_n\cap B)\\ &=P(A_1|B)\times P(A_1)+P(A_2|B)\times P(A_2)+\cdots+P(A_n|B)\times P(A_n) \end{align} \tag{6.13}\]
Aplicando as equações 6.8 e 6.13, para qualquer acontecimento \(A_k\), com \(k\in\lbrace 1, 2,\cdots,n\rbrace\), podemos determinar \(P(A_k|B)\):
\[ \begin{align} P(A_k|B) &= \frac{P(B|A_k)\times P(A_k)}{P(B)}\\ &= \frac{P(B|A_k)\times P(A_k)}{P(A_1|B)\times P(A_1)+P(A_2|B)\times P(A_2)+\cdots+P(A_n|B)\times P(A_n)}\\ &=\frac{P(B|A_k)\times P(A_k)}{\sum_{i=1}^n P(A_i|B)\times P(A_i)} \end{align} \tag{6.14}\]
A aplicação da Equação 6.14 nas condições enunciadas é conhecida como o Teorema de Bayes. O diagrama de Venn da Figura 6.6 permite uma possível visualização do significado dos vários conjuntos.
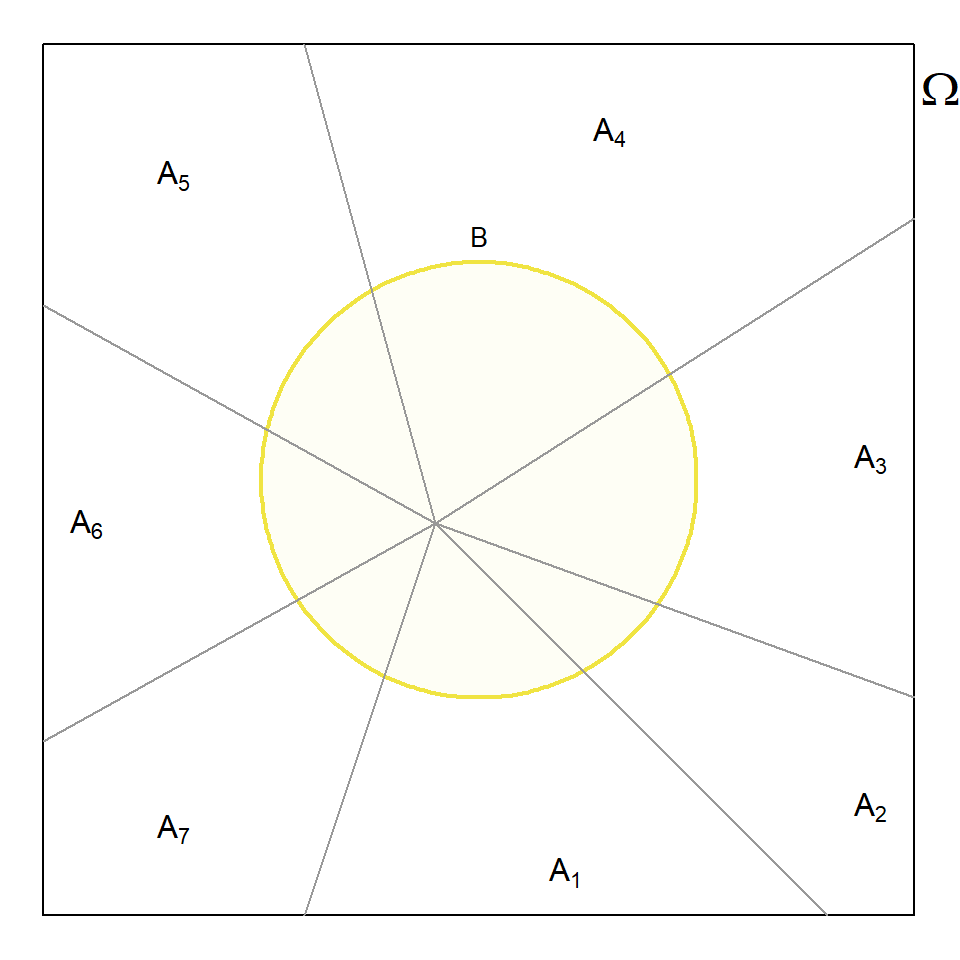
Como se pode verificar, os conjuntos \(A_1\), \(A_2\), … \(A_n\) são mutuamente exclusivos e preenchem a totalidade do espaço amostral. O conjunto \(B\) interseta os vários conjuntos com probabilidades diferentes.
Fundamentalmente, o teorema de Bayes permite atualizar o grau de crença na ocorrência de um determinado evento, \(A_k\), na presença de um facto novo, neste caso, a ocorrência de \(B\). Para uma melhor compreensão deste importante e interessante tópico da Estatística, recomenda-se a visualização do vídeo da Figura 6.7.
Tutoriais
Depois de ler este capítulo pode verificar como são implementados estes conceitos no ambiente computacional R. Os tutoriais listados abaixo estão diretamente relacionados com este capítulo.
| Tutorial | Descrição |
|---|---|
| Técnicas de Contagem | Demonstração da aplicação das técnicas de contagem mais frequentes, especialmente úteis na presença de populações de pequena dimensão. |
Nenhum item correspondente
Esta conclusão é válida ao considerar a experiência aleatória que consiste em escolher ao acaso um dos alunos do estudo. Se aquele conjunto de alunos fosse uma amostra aleatória e se o objetivo fosse inferir sobre a independência na população o procedimento seria insuficiente, pois seria necessário considerar a variabilidade amostral.↩︎