Cabelo |
|||||
|---|---|---|---|---|---|
| Olhos | Black | Blond | Brown | Red | Total |
| Blue | 20 | 94 | 84 | 17 | 215 |
| Brown | 68 | 7 | 119 | 26 | 220 |
| Green | 5 | 16 | 29 | 14 | 64 |
| Hazel | 15 | 10 | 54 | 14 | 93 |
| Total | 108 | 127 | 286 | 71 | 592 |
| a Intencionalmente, os nomes das cores não foram traduzidos. | |||||
5 Dados Bivariados
Nesta secção são apresentadas as principais técnicas para descrever o relacionamento entre duas variáveis. No final do capítulo aborda-se, de forma sumária, algumas alternativas para incluir mais do que duas variáveis numa visualização.
A secção está organizada segundo o tipo de variáveis envolvidas: ambas categóricas (Secção 5.1), uma categórica e uma numérica (Secção 5.2) ou ambas numéricas (Secção 5.3). No final aborda-se o caso de se pretender envolver mais do que duas variáveis (Secção 5.4).
5.1 Duas variáveis categóricas
Quando se está perante duas variáveis categóricas, a informação pode ser visualizada num gráfico de barras ou num gráfico em mosaico. Também é possível medir o grau de independência das variáveis através de estatísticas adequadas que não se apresentam neste capítulo.
Para ilustrar estas visualizações vamos utilizar o conjunto de dados do R HairEyeColor, que contém a cor do cabelo e a cor dos olhos de um conjunto de alunos. A Tabela 5.1 mostra uma tabela de contingência cruzada para as duas variáveis.
5.1.1 Gráfico de barras
O gráfico de barras é a ferramenta de eleição para representar informação categórica. No caso de haver duas variáveis o gráfico pode ser apresentado em três variantes: barras sobrepostas, barras agrupadas e barras sobrepostas normalizadas. Vamos analisar as três variantes. Em qualquer das variantes, o eixo horizontal apresenta uma das variáveis e o eixo vertical representa frequências. A segunda variável é apresentada utilizando cores.
Barras sobrepostas
Num gráfico de barras sobrepostas, as frequências da segunda variável são sobrepostas na mesma barra, utilizando cores diferentes. A Figura 5.1 exemplifica o que foi dito. A mesma informação pode ser apresentada de duas formas, trocando as variáveis entre o eixo horizontal e a legenda. Naturalmente, deve ser preferida a figura que melhor ilustre as conclusões.
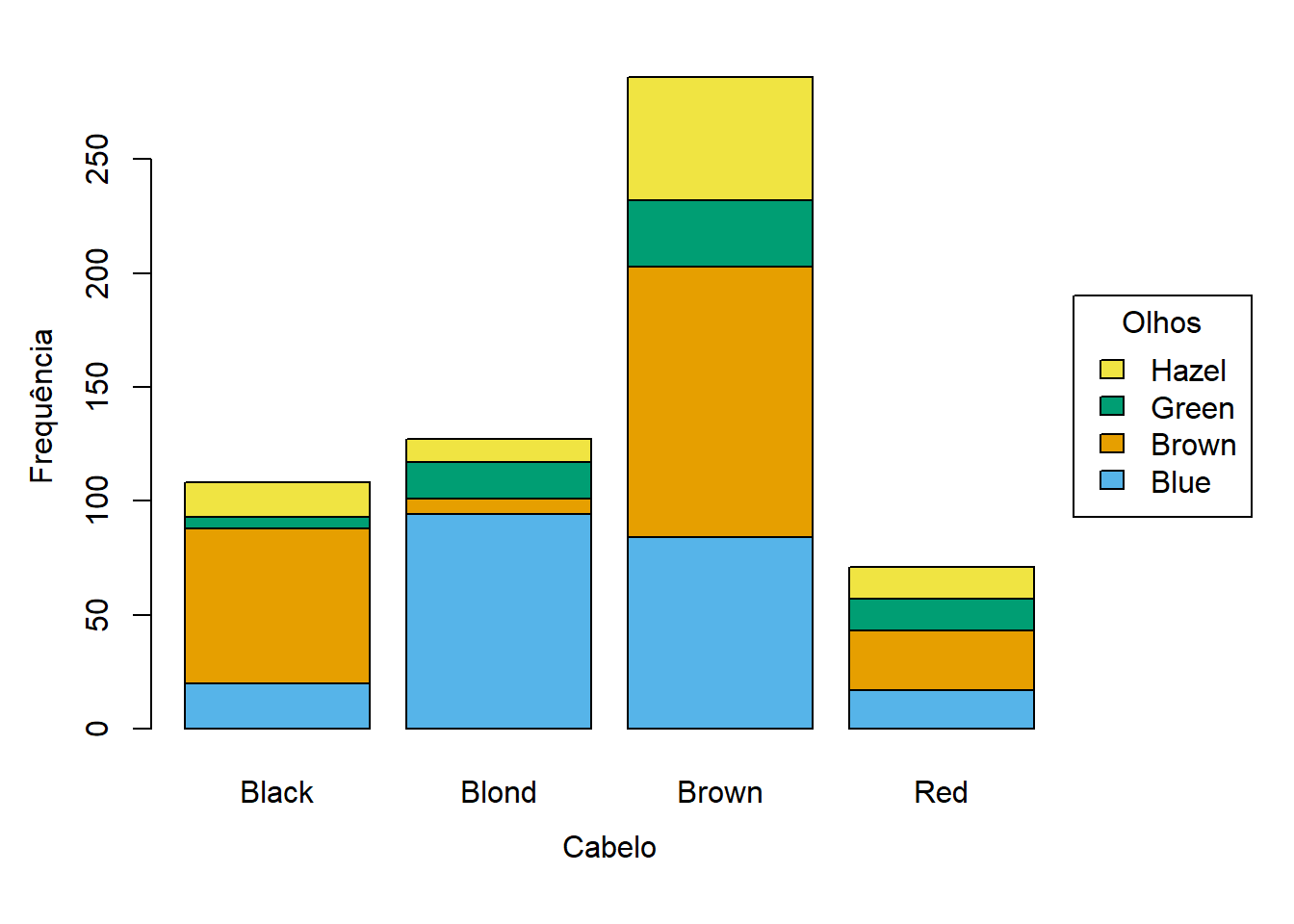
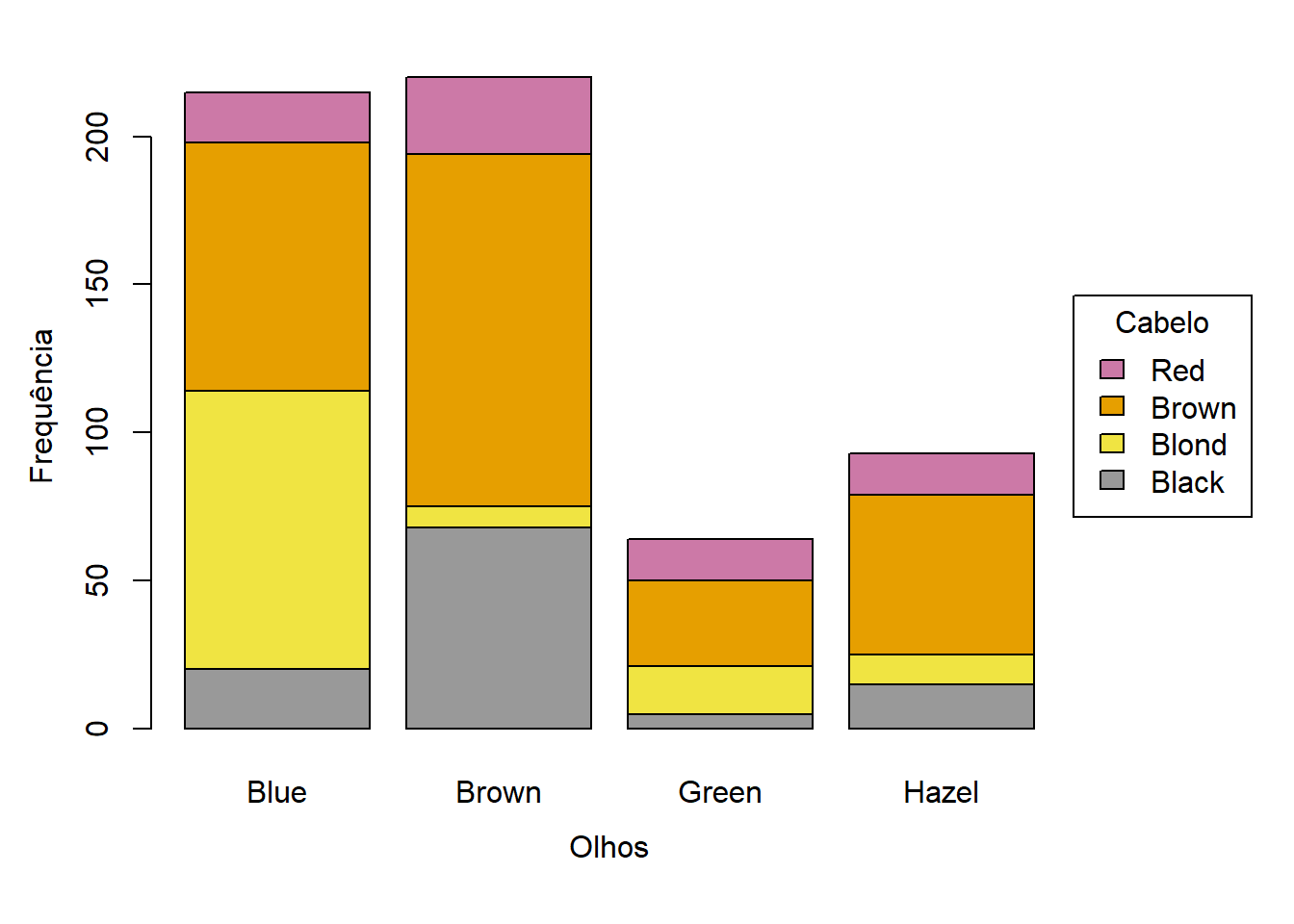
Neste gráfico, as comparações entre categorias da segunda variável são difíceis de fazer, especialmente se as barras ou os segmentos tiverem tamanhos muito diferentes.
Barras agrupadas
Em vez de sobrepor vários segmentos numa barra, pode criar-se uma barra para cada categoria da segunda variável e agrupar as barras. A Figura 5.2 ilustra este tipo de gráfico.
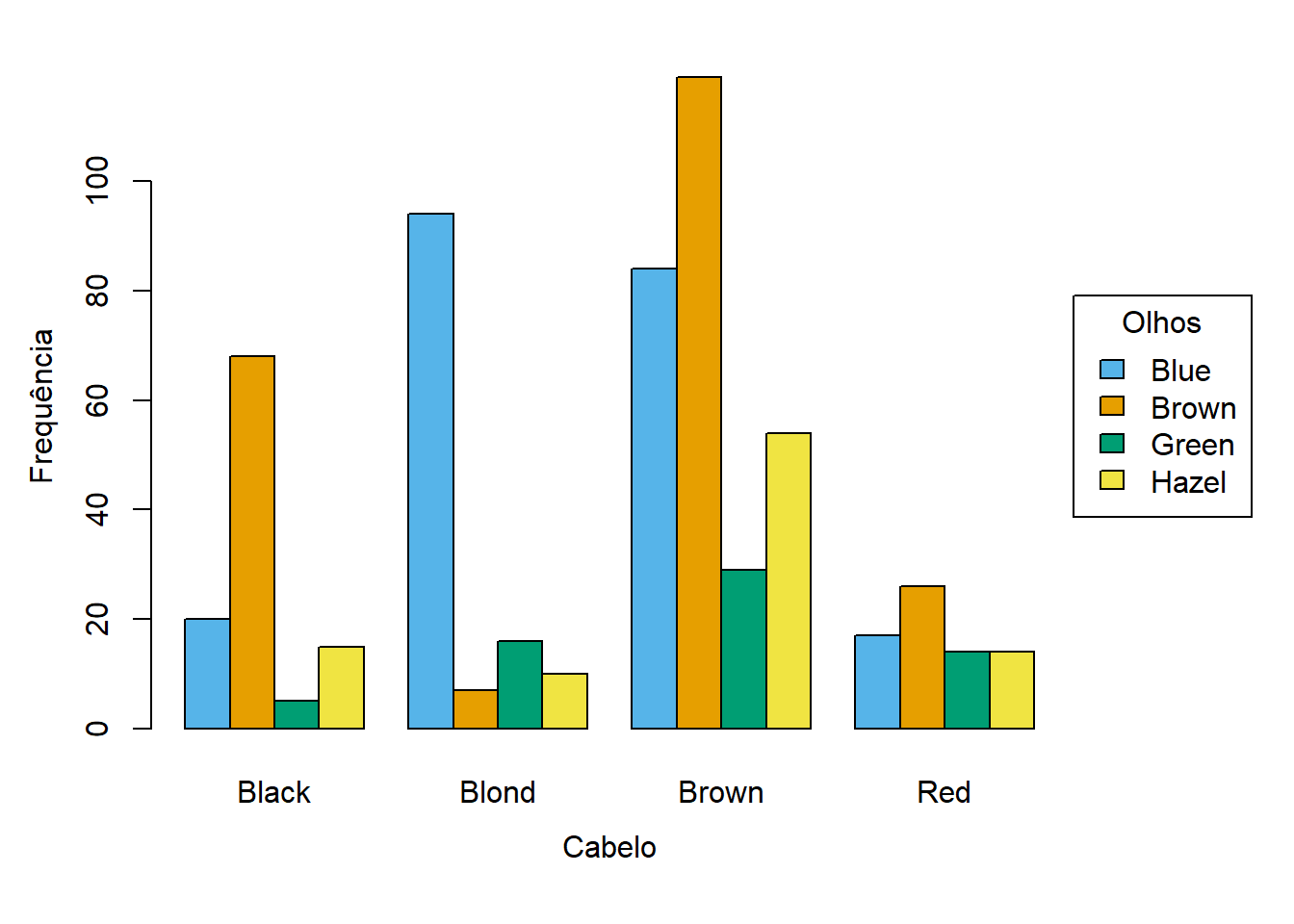
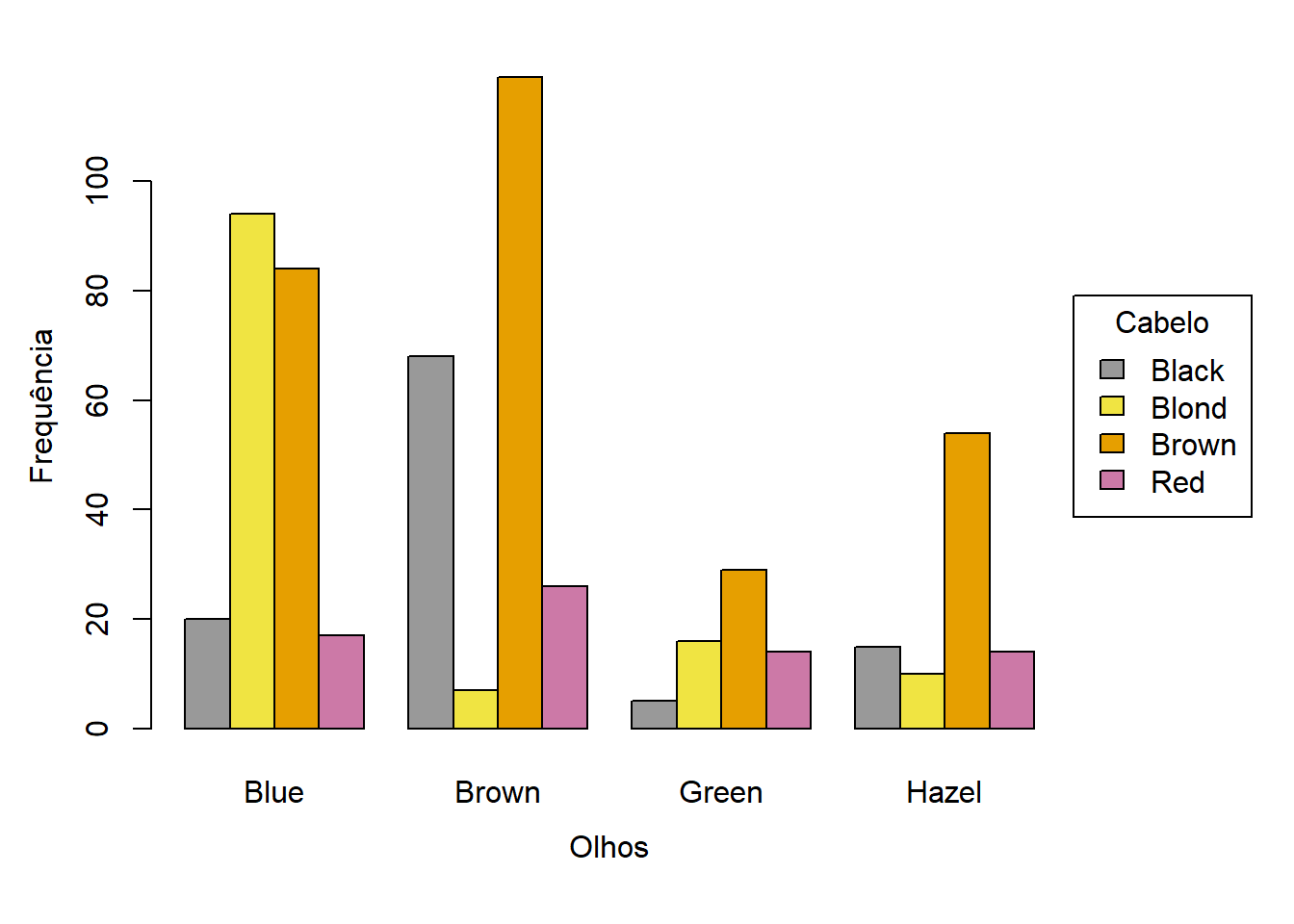
Neste caso, é fácil comparar as categorias da segunda variável, mas dificulta a perceção dos totais para cada categoria em ambas as variáveis. Esta alternativa pode gerar gráficos confusos, caso haja muitas categorias.
Barras sobrepostas normalizadas
Uma última alternativa para visualizar a informação consiste em normalizar a altura das colunas para 1 unidade ou 100%. A Figura 5.3 apresenta esta alternativa.


Esta variante facilita a comparação de categorias, mas não é possível ajuízar as frequências absolutas em cada categoria.
Importante
Como se pode constatar, mesmo com uma visualização simples, existem inúmeras alternativas relativamente à ordem das variáveis, à ordem das categorias, etc. A alternativa mais adequada depende daquilo que se quer salientar. A escolha do melhor gráfico envolve um processo de experimentação por tentativa e erro até obter resultados satisfatórios.
5.1.2 Gráfico em mosaico
Uma outra forma de visualizar a relação entre duas variáveis categóricas é o gráfico em mosaico. No fundo, trata-se de uma variante ao gráfico de barras em que a largura das barras é proporcional às frequências na categoria respetiva. A Figura 5.4 mostra duas variantes em que apenas se trocaram as variáveis de eixo. Neste caso foram utilizadas cores, mas o gráfico também é aceitável com apenas uma cor.


Neste gráfico são claras as proporções para cada variável e a proporção global de cada célula, no entanto, se houver muitas categorias o gráfico torna-se difícil de interpretar.
5.2 Uma variável categórica e uma numérica
Quando se está perante uma variável numérica e uma variável categórica, por norma, pretende-se avaliar as diferenças entre as várias categorias que a variável numérica apresenta. Naturalmente, as estatísticas referidas para uma variável (média, desvio padrão, etc.) podem ser calculadas e analisadas para cada grupo de observações. Graficamente, há duas alternativas genéricas:
No mesmo gráfico, utilizar diferentes elementos visuais para diferenciar as categorias. Esta abordagem pode ser estendida a mais do que duas variáveis.
Segmentar os dados da variável contínua por categoria e elaborar um subgráfico para cada categoria.
Para ilustrar as diferentes alternativas vamos utilizar o conjunto de dados chickwts disponível no R. Estes dados contêm o peso de 6 conjuntos de frangos com 6 semanas após terem sido alimentados com diferentes dietas. Na Tabela 5.2 apresentam-se algumas estatísticas para cada dieta.
chickwts)
| Dieta | Mínimo | Q1 | Mediana | Média | Q3 | Máximo |
|---|---|---|---|---|---|---|
| casein | 216 | 277.25 | 342.0 | 323.5833 | 370.75 | 404 |
| horsebean | 108 | 137.00 | 151.5 | 160.2000 | 176.25 | 227 |
| linseed | 141 | 178.00 | 221.0 | 218.7500 | 257.75 | 309 |
| meatmeal | 153 | 249.50 | 263.0 | 276.9091 | 320.00 | 380 |
| soybean | 158 | 206.75 | 248.0 | 246.4286 | 270.00 | 329 |
| sunflower | 226 | 312.75 | 328.0 | 328.9167 | 340.25 | 423 |
| a Intencionalmente, os nomes das dietas não foram traduzidos. |
Uma forma de visualizar os dados consiste na utilização de um diagrama de extremos e quartis para cada categoria, apresentados no mesmo gráfico. A Figura 5.5 apresenta duas versões do gráfico referido.


Na versão 5.5 (b), ao contrário da versão 5.5 (a) são utilizadas cores. Neste caso, a utilização da cor é redundante e não acrescenta nada à compreensão do gráfico, sendo preferível a primeira versão. Se o gráfico estiver inserido num conjunto de materiais em que se associa uma cor a cada categoria, fará sentido utilizar cores.
Caso se pretenda ter mais detalhes sobre a distribuição, uma outra forma de visualizar os dados consiste em segmentar o gráfico em vários subgráficos, um por cada categoria. A Figura 5.6 mostra o resultado quando se aplica a segmentação ao histograma.

Note-se o cuidado de utilizar as mesmas escalas para todos os histogramas com o objetivo de facilitar a comparação entre histogramas.
Esta técnica – utilização de uma (ou mais) variável categórica para segmentar os dados – não se limita ao histograma e pode ser utilizada para outro tipo de gráficos.
No caso do histograma, encontram-se com alguma frequência casos em que são colocados dois ou mais histogramas no mesmo gráfico, utilizando barras de cor diferente para separar visualmente as categorias. A não ser em casos muito concretos, com poucas (2) categorias e pouca sobreposição, tende a resultar num gráfico confuso. Na Figura 5.7 exemplifica-se a colocação de dois histogramas no mesmo gráfico usando cores diferentes.
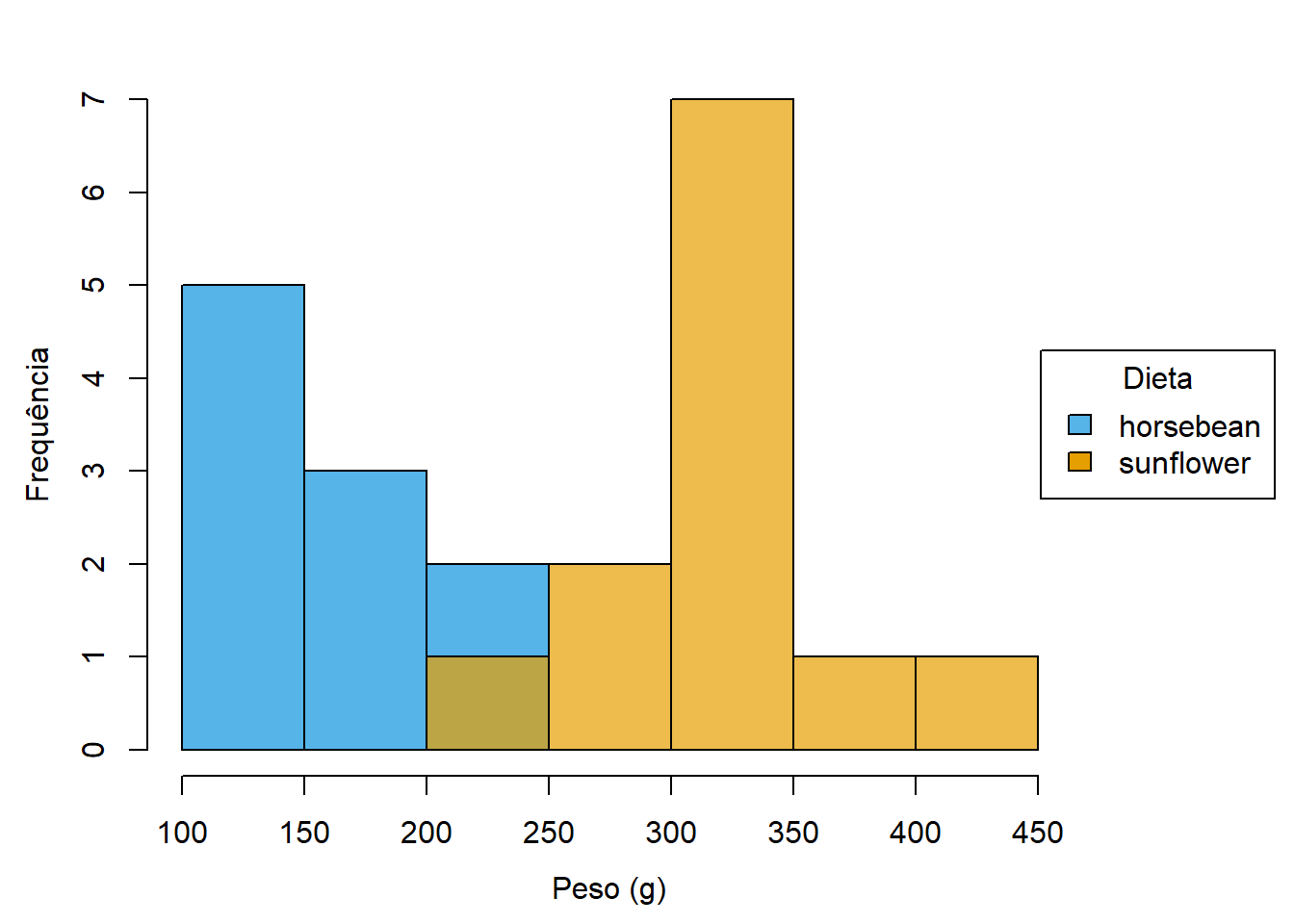
Note-se que, mesmo com apenas duas categorias e uma zona de sobreposição reduzida, o gráfico é confuso, sendo muito mais clara a Figura 5.6. Claramente, é um tipo de gráfico que não se recomenda.
Importante
Tipicamente, na presença de uma variável categórica e de uma variável numérica, o objetivo é verificar se a variável numérica se comporta da mesma forma para as diversas categorias.
5.3 Duas variáveis numéricas
Perante duas variáveis numéricas o objetivo da análise descritiva passa por estudar como elas estão relacionadas. Mais uma vez, pode recorrer-se ao cálculo de estatísticas e a métodos gráficos.
5.3.1 Diagrama de dispersão
O diagrama de dispersão, muitas vezes designado em inglês por scatter plot, é um digrama de pontos em que cada ponto representa o par de observações para as variáveis envolvidas, estando uma variável associada ao eixo horizontal e a outra associada ao eixo vertical.
Para ilustrar os conteúdos desta secção vai-se utilizar o conjunto de dados trees disponível no R. Este conjunto de dados contém medições do diâmetro (em polegadas) e da altura (em pés) relativos a 31 árvores da mesma espécie. A Figura 5.8 mostra o diagrama de dispersão para estes dados.

O diagrama de dispersão permite avaliar o tipo e o grau de relacionamento entre as variáveis. O tipo de relacionamento pode ser classificado em:
Positivo: tendencialmente, as variáveis variam conjuntamente no mesmo sentido, isto é, quando uma aumenta a outra também aumenta.
Negativo: tendencialmente, as variáveis variam conjuntamente em sentidos opostos, isto é, quando uma aumenta a outra diminui.
No caso da Figura 5.8 parece haver um relacionamento positivo entre as variáveis, o que faz sentido, pois o diâmetro e a altura das árvores tendem ambos a aumentar com a idade.
5.3.2 Ajuste de uma linha de tendência
Para melhor visualizar o tipo de relacionamento entre as variáveis pode estimar-se uma relação linear. Uma relação linear é uma reta ajustada aos dados. Se a reta for definida pela equação reduzida, \(y=a+bx\), estimar a relação linear corresponde a estimar os valores das constantes \(a\) e \(b\).
Embora este assunto vá ser aprofundado no capítulo relativo à regressão, para estimar os valores de \(a\) e \(b\) é necessário definir uma medida de ajuste. Como a reta ajustada faz uma estimativa do valor de \(y\) para um determinado valor de \(x\), podemos definir o erro de ajuste, \(e_i\), para cada observação, como a diferença entre o valor de \(y_i\) e o valor estimado pela reta, \(\hat{y_i}\), ou seja, para cada observação, \(e_i\) é dado por
\[e_i = y_i - \hat{y_i} = y_i - (a + bx_i) \tag{5.1}\]
Os erros de ajuste podem ser visualizados na Figura 5.9. Como se pode verificar vão existir erros positivos (pontos acima da reta) e erros negativos (pontos abaixo da reta), havendo uma infinidade de retas que igualam a soma dos erros a 0, por exemplo, qualquer reta que passe pelo ponto \((\bar{x}, \bar{y})\).

Para estimar o melhor ajuste é utilizado o método dos mínimos quadrados, que consiste em minimizar a soma dos erros elevados ao quadrado, \(SEQ\), definida como
\[SEQ=\sum_i e_i = \sum_i y_i - (a + bx_i) \tag{5.2}\]
Para determinar os valores de \(a\) e \(b\) que minimizam aquela soma, utilizam-se derivadas. Seja \(SEQ(a, b)\) uma função de \(a\) e \(b\) que resulta na soma dos erros aos quadrado para um determinado conjunto de dados. Para determinar \(a\) e \(b\) basta resolver o seguinte sistema de equações:
\[ \begin{cases} \frac{\partial SEQ(a,b)}{\partial a} = 0 \\ \frac{\partial SEQ(a,b)}{\partial b} = 0 \end{cases} \tag{5.3}\]
A resolução do sistema de equações (omitida, é um bom exercício) resulta em
\[ \begin{cases} b= \frac{\sum_i(x_i-\bar{x})(y_i-\bar{y})}{\sum_i(x_i-\bar{x})^2} = \frac{S_{xy}}{S_{xx}} \\ a= \bar{y} - b\bar{x} \end{cases} \tag{5.4}\]
O coeficiente de correlação de Pearson é uma medida de associação que pode variar entre -1 (associação linear negativa perfeita) e 1 (associação linear positiva perfeita).
Exercício 5.1 (Cálculo dos coeficientes \(a\) e \(b\)) Considere os dados usados na Figura 5.9:
- Variável \(x\): 1, 2, 3, 4, 5, 6, 7
- Variável \(y\): 3, 2, 6, 3, 7, 8, 6
Para estimar os valores de \(a\) e \(b\):
Começar por calcular as médias. Deve obter \(\bar{x}=4\) e \(\bar{y}=5\).
Calcular as diferenças:
- \((x_i-\bar{x})\), obtendo: -3, -2, -1, 0, 1, 2, 3
- \((y_i-\bar{y})\), obtendo -2, -3, 1, -2, 2, 3, 1
Calcular os produtos:
- \((x_i-\bar{x})(y_i-\bar{y})\), obtendo: 6, 6, -1, 0, 2, 6, 3
- \((x_i-\bar{x})^2\), obtendo: 9, 4, 1, 0, 1, 4, 9
Calcular \(S_{xy}\) e \(S_{xx}\). Deverá obter \(S_{xy} = 22\) e \(S_{xx} = 28\).
Calcular \(b = \frac{S_{xy}}{S_{xx}} = \frac{22}{28} \approx 0.79\)
Calcular \(a= \bar{y} - b\bar{x} = 5 - 0.79\times 4 \approx 1.86\)
NotaExpressões alternativas
\[S_{xy} = \sum_i(x_i-\bar{x})(y_i-\bar{y}) = \sum_i x_i y_i - n\bar{x}\bar{y}\] \[S_{xx} = \sum_i(x_i-\bar{x})^2 = \sum_i x_i^2 - n\bar{x}^2\]
\[S_{yy} = \sum_i(y_i-\bar{y})^2 = \sum_i y_i^2 - n\bar{y}^2\]
Procedendo de forma semelhante ao Exercício 5.1, utilizando os dados do conjunto trees, apresentam-se novamente na Figura 5.10 os dados, a que se adicionou a relação linear ajustada.

Importante
É sempre possível ajustar uma relação linear a um conjunto de dados (excetuando o caso de todos os valores de da variável \(X\) serem todos iguais, que não tem qualquer interesse prático). O facto de se poder calcular um ajuste linear não significa que as variáveis tenham uma relação linear ou que existe uma relação de causa e efeito. São apenas cálculos, que devem ser interpretados no contexto dos dados.
Por exemplo, na Figura 5.10 pode verificar-se que os erros não estão distribuídos de forma aproximadamente simétrica em torna da reta. Isto indica que a relação entre as variáveis, provavelmente, não é linear.
5.3.3 Coeficiente de correlação
A análise visual feita na Secção 5.3.2 pode não ser muito precisa, pois é baseada na perceção do diagrama de dispersão que, em larga medida, é subjetiva. Nesta secção propõe-se algumas estatísticas para avaliar o relacionamento de duas variáveis de forma mais assertiva.
Podemos inferir se a associação entre duas variáveis é positiva ou negativa, através do sinal do coeficiente \(b\). Na Equação 5.4 pode verificar-se que o sinal de \(b\) é igual ao sinal do produto cruzado \(S_{xy}\), uma vez que \(S_{xx}\) terá que ser não negativo.
Dividindo o produto cruzado \(S_{xy}\) pelo número de observações menos 1 (tal como no cálculo da variância) obtém-se uma medida designada por covariância, \(cov_{xy}\).
\[cov_{xy} = \frac{S_{xy}}{n-1} = \frac{(x_i-\bar{x})(y_i-\bar{y})}{n-1} \tag{5.5}\]
Embora se possa estabelecer o sentido da associação entre as variáveis a partir do sinal da covariância, o valor absoluto da covariância é difícil de interpretar, pois depende da escala na qual as variáveis estão expressas.
Por este motivo, dividindo a covariância pelo produto dos desvios padrão obtem-se uma medida adimensional mais fácil de interpretar: o coeficiente de correlação (de Pearson), \(r_{xy}\).
\[r_{xy} = \frac{cov_{xy}}{s_x s_y} \tag{5.6}\]
Exercício 5.2 (Cálculo do coeficiente de correlação) Tomando novamente os dados do Exercício 5.1, comece-se por calcular a covariância:
\[cov_{xy} = \frac{S_{xy}}{n-1} = \frac{22}{7-1} \approx 3.67\]
É necessário também calcular o valor do desvio padrão de ambas as variáveis, obtendo-se \(s_x \approx 2.16\) e \(s_y \approx 2.31\).
Agora pode-se calcular o valor do coeficiente de correlação amostral:
\[r_{xy} = \frac{cov_{xy}}{s_x s_y} = \frac{3.67}{2.16\times 2.31} \approx 0.735\]
O coeficiente de correlação linear (Pearson) mede o grau de associação linear entre as variáveis. No entanto, a não existência de uma relação linear não significa que não haja uma relação. Na Figura 5.11 mostram-se vários conjuntos de dados e os respetivos coeficientes de correlação linear.

Relativamente à Figura 5.11 verifica-se o seguinte:
Perante uma relação linear, o coeficiente aproxima-se de -1 ou de 1 conforme o conjunto de pontos mais se aproxime da colineariedade, sendo 0 quando não existe qualquer tipo de correlação (linha 1).
Perante uma relação linear perfeita, o coeficiente de correlação é sempre igual a -1 ou a 1, apenas dependendo do sinal do declive que os pontos formam (linha 2).
Coeficientes de correlação elevados não implicam necessariamente uma relação linear, havendo muitas relações não lineares que apresentam coeficientes elevados (linha 3).
Um coeficiente de correlação nulo não implica a inexistência de padrões de relacionamento entre as variáveis. Apenas não se trata de relações lineares (linha 4).
Dica
- Um coeficente de correlação linear elevado não significa necessariamente que haja uma relação linear entre as variáveis, pode haver ou não haver.
- Um coeficiente de correlação linear nulo não significa que as variáveis não possam estar relacionadas.
- É sempre necessário inspecionar o digrama de dispersão!
NotaExpressão alternativa para o cálculo do coeficiente de correlação
O coeficiente de correlação também pode ser calculado com a Equação 5.7, especialmente útil para cálculos manuais.
\[r_{xy} = \frac{S_{xy}}{\sqrt{S_{xx}}\sqrt{S_{yy}}} = \frac{\sum_i x_i y_i - n\bar{x}\bar{y}} {\sqrt{\sum_i x_i^2 - n\bar{x}^2} \sqrt{\sum_i y_i^2 - n\bar{y}^2}} \tag{5.7}\]
Note-se também que
\[r_{xy} = b\frac{\sqrt{S_{xx}}}{\sqrt{S_{yy}}} \tag{5.8}\]
que mostra que o coeficiente de correlação é nulo quando o declive da relação linear ajustada é nulo.
5.3.4 Coeficiente de determinação
Uma outra medida que pode ser utilizada para medir o grau de relacionamento entre duas variáveis numéricas é o coeficiente de determinação, \(r_{xy}^2\), ou seja, o quadrado do coeficiente de correlação.
\[r_{xy}^2 = \frac{S_{xy}^2}{S_{xx} S_{yy}} = b^2 \frac{S_{xx}}{S_{yy}} \tag{5.9}\]
Manipulando as expressões apresentadas ao longo das secções anteriores, consegue-se demonstrar que
\[r_{xy}^2 = \frac{\sum_i(\hat{y_i}-\bar{y})^2}{\sum_i(y_i-\bar{y})^2} \tag{5.10}\]
Note-se que, para cada observação,
\[y_i-\bar{y} = (y_i-\hat{y_i})+(\hat{y_i}-\bar{y}) = e_i+(\hat{y_i}-\bar{y}) \tag{5.11}\]
A interpretação geométrica da Equação 5.11 pode ser visualizada na Figura 5.12.

A relação estimada prevê que, quando a variável \(X\) se altera de \(\bar{x}\) para \(x_i\), o valor de \(Y\) deve passar de \(\bar{y}\) para \(\hat{y_i}\) (variação explicada). A diferença entre o valor de \(y_i\) e \(\hat{y_i}\) é o erro da previsão ou estimativa (variação não explicada). Estas duas diferenças somadas são iguais à diferença entre \(y_i\) e \(\bar{y}\) (variação total).
Neste contexto, através da Equação 5.10, podemos entender o \(r_{xy}^2\) como o quociente entre a variação em \(Y\) que a reta ajustada explica e a variação total em \(Y\). Este quociente será um valor entre 0 e 1 e pode ser entendido como a proporção de variação que a reta ajustada explica. Naturalmente, quanto mais as observações estiverem próximas da reta ajustada, mais o coeficiente de determinação se aproxima de 1.
Uma outra forma de expressar o coeficiente de determinação é
\[r_{xy}^2 = 1 - \frac{\sum_i(y_i - \hat{y_i})^2}{\sum_i(y_i-\bar{y})^2} = 1- \frac{\sum_i e_i^2}{S_{yy}} \tag{5.12}\]
Importante
Os termos variação explicada e variação não explicada podem induzir a presunção de uma relação de causa e efeito entre as variáveis. Nunca é demais relembrar que, a não ser que os dados provenham de uma experiência desenhada para poder inferir tal relação, as conclusões são meramente correlacionais (Capítulo 2).
Relembrando: correlação \(\neq\) causa e efeito.
5.3.5 Séries cronológicas
Um caso particular de dados bivariados envolve as séries cronológicas. Neste caso os valores da série dizem respeito a intervalos de tempo regulares. Por exemplo, as vendas semanais de uma loja são uma série temporal. Como os valores da série estão referidos em função do tempo, o tempo será a outra variável.
No caso de séries temporais o diagrama de dispersão, onde apenas aparecem pontos, costuma ser substituído por um diagrama semelhante, mas com linhas em vez de pontos. A ideia é mostrar a evolução da variável ao longo do tempo.
Na Figura 5.13 é representada desta forma a série cronológica AirPassengers disponível no R. A série diz respeito ao número mensal de passageiros transportados (em milhares) entre 1949 e 1960.

Neste tipo de gráfico é possível visualizar tendências e sazonalidade e é ideal para este tipo de dados.
Para lá da representação gráfica, as séries cronológicas apresentam características que as tornam muito diferentes de outro tipo de dados e exigem técnicas específicas. Por exemplo, as observações de um período costumam estar correlacionadas as observações desfasadas um determinado intervalo. Por este motivo, o tratamento de séries cronológicas sai do âmbito deste texto.
Importante
As séries cronológicas são variáveis especiais, tendo características que exigem técnicas diferentes das variáveis comuns. Se necessitar de tratar este tipo de dados, deve consultar um texto especializado, por exemplo, Hyndman & Athanasopoulos (2021).
5.4 Mais de duas variáveis
Nesta secção faz-se uma breve referência ao caso de haver mais do que duas variáveis a descrever de forma conjunta, mencionando apenas como podem os métodos gráficos já abordados ser adaptados.
Como a representação gráfica é bidimensional, para incluir uma terceira variável, uma das alternativas é utilizar a perspetiva. Desta forma, se houver 3 variáveis numéricas pode ser construído um gráfico de dispersão tridimensional ou uma superfície tridimensional, tal como na Figura 5.14.



Foi utilizada a mesma informação para produzir os 3 diagramas apresentados na Figura 5.14. Enquanto que nas figuras 5.14 (a) e 5.14 (b) a variável z aparece num terceiro eixo e é utilizada uma perspetiva tridimensional, em 5.14 (c) a figura é bidimensional e é utilizada a cor para representar a intensidade da variável z (tipicamente, essa informação é colocada numa legenda que, neste caso, foi omitida).
Embora a representação tridimensional seja adequada em situações específicas, a utilização da perspetiva pode levar a gráficos complexos e difíceis de interpretar. Por exemplo na Figura 5.14 (a) os dados de um dos quadrantes estão ocultos por trás da figura representada, não se conseguindo visualizar todos os dados da mesma forma. Já na Figura 5.14 (b), a representação é algo confusa.
Por este motivo, o mais frequente é fazer algo semelhante à Figura 5.14 (c): representar variáveis adicionais (pode ser mais do que uma) utilizando elementos visuais (cores, tamanhos, formas), acompanhando a figura de uma legenda para ajudar à interpretação.
No caso da Figura 5.14, as 3 variáveis são numéricas. No entanto, é frequente nem todas as variáveis serem numéricas. Na Secção 5.2 já se apresentou uma técnica que pode ser utilizada para lidar com variáveis categóricas adicionais: utilizar um subgráfico para representar o conjunto de observações onde a variável categórica toma determinado nível. A Figura 5.6 exemplificou a técnica para o caso do histograma. Naturalmente, a mesma técnica pode ser implementada para outras visualizações.
Utilizando o conjunto de dados mtcars, a figura Figura 5.15 apresenta diagramas de dispersão para as variáveis disp (cilindrada, em polegadas cúbicas) e mpg (consumo, em milhas por galão). Adicionou-se à visualização a variável am, do tipo nominal, que indica o tipo de transmissão de cada carro, automática ou manual.




Nas figuras 5.15 (a) e 5.15 (b) cada tipo de transmissão foi representado num subgráfico. Para facilitar a comparação, note que ambos os gráficos utilizam as mesmas escalas. Na Figura 5.15 (c), utilizou-se a cor para diferenciar o tipo de transmissão de cada carro observado. Já na Figura 5.15 (d), utilizaram-se símbolos diferentes para fazer a distinção. Como se pode observar, a cor parece ser mais eficaz a transmitir a informação.
Naturalmente, quanto mais elementos visuais se colocarem no gráfico, mais difícil se torna a interpretação. Logo, deve ser exercida parcimónia na quantidade de informação que se coloca num gráfico, pois é fácil exagerar e a visualização perder a eficácia.
Como se pode inferir, as possibilidades são ilimitadas e poder-se-iam escrever-se livros inteiros sobre o assunto. Há dezenas de gráficos específicos para determinadas áreas. Nesta secção apenas se pretendeu fazer uma menção muito superficial, uma vez que, no resto do texto, todas as visualizações utilizadas são, quase sempre, simples.
Tutoriais
Depois de ler este capítulo pode verificar como são implementados estes conceitos no ambiente computacional R. Os tutoriais listados abaixo estão diretamente relacionados com este capítulo.
| Tutorial | Descrição |
|---|---|
| Gráficos | Noções fundamentais sobre a elaboração de gráficos no R. |
| Gráfico de Barras | Construção de tabelas de contingência e gráficos de barras no R, para uma ou duas variáveis categóricas. |
| Diagramas de Extremos e Quartis | Construção e configuração de diagramas de extremos e quartis no R. |
Nenhum item correspondente
Algumas ideias para as figuras e para o código foram inspiradas em DenisBoigelot, original uploader was Imagecreator, CC0, via Wikimedia Commons.↩︎